Twitter is an absolute treasure trove for any data scientist, whether they be a professional, student or hobbyist. It connects people from all walks of life, whether you are an aspiring musician or you are Taylor Swift, whether you are a rec-league basketball player or LeBron James, all the way from local politicians to the current and past presidents of the United States.
How broad is its user base, and how much data does it generate? As of Q3 2019, Twitter’s daily active user base was about 145 million people, and in 2018 half a billion tweets were being sent out every day. Even with its 280-character limit, it is no surprise that Twitter data presents a fertile ground from which data insights can be harvested.
But then — how do we collect some of this data? In fact, for various reasons — there are limited, pre-compiled repositories of Twitter data. Twitter itself on special occasions might make its own compilations of data available, they are few and far between. They might even not be publicly available — only for a select group of developers and researchers, like this COVID-19 related dataset.
That’s why I wanted to spend some time in this post comparing two popular third party Python packages, Tweepy and Twint.
Both of these are tremendously popular repositories, as you see in the graph of its GitHub popularity below.
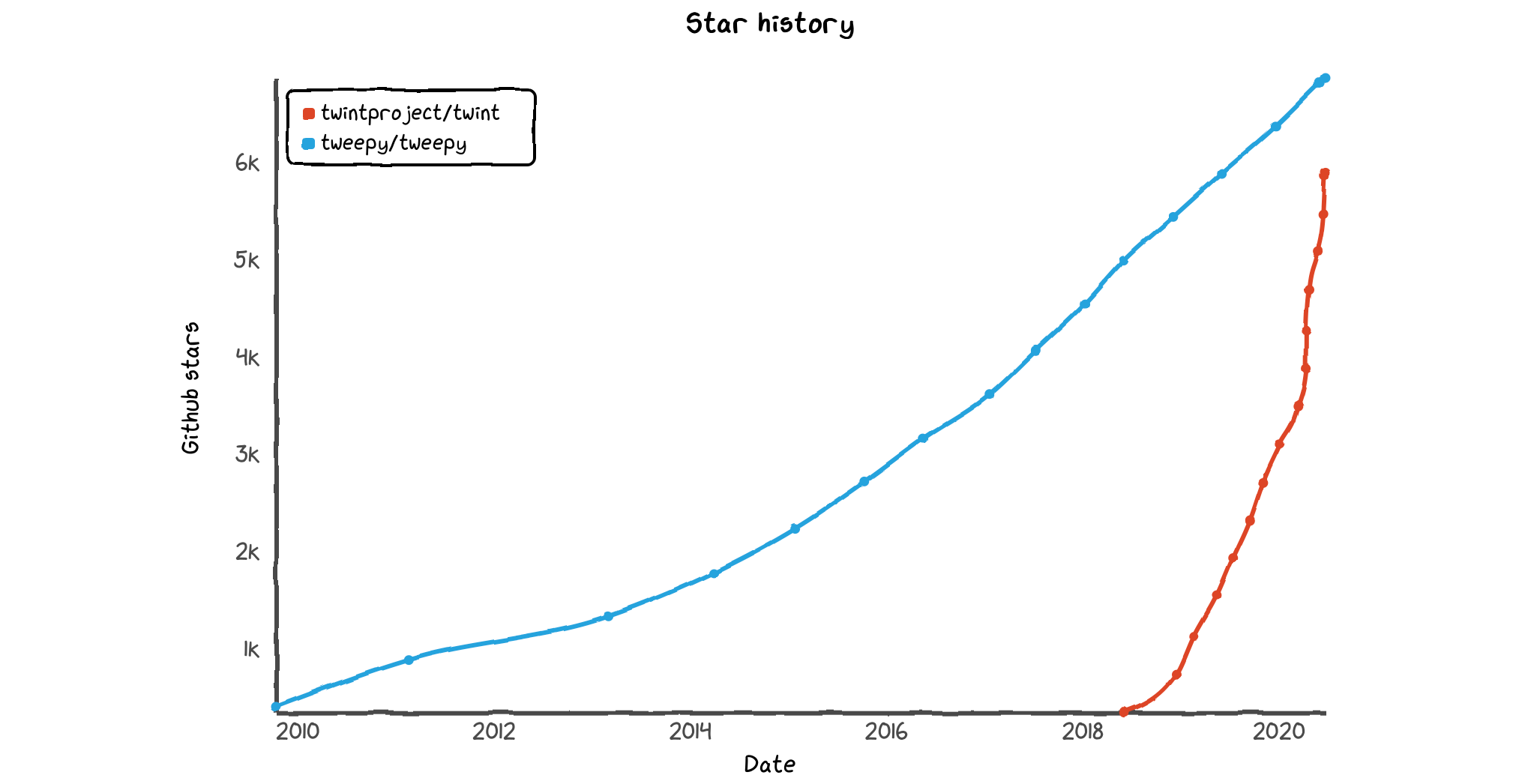
Twint and Tweepy — GitHub Star History (https://star-history.t9t.io/)
#python #twitter #data-science #programming