The scikit-learn’s transformers API is a great tool for data cleaning, preprocessing, feature engineering, and extraction. Sometimes, however, none of the wide range of available transformers matches the specific problem at hand. On these occasions, it is handy to be able to write one oneself. Luckily, it’s straightforward to leverage scikit-learn’s classes to build a transformer that follows the package’s conventions and can be included in the scikit-learn pipelines.

Problem setting
To make it practical, let’s look at an example. We have a data set called TAO which stands for Tropical Atmosphere Ocean. It contains some weather measurements such as temperature, humidity, or wind speed. A subsample of these data comes with the R library VIM. Here, we are working with a slightly preprocessed version.
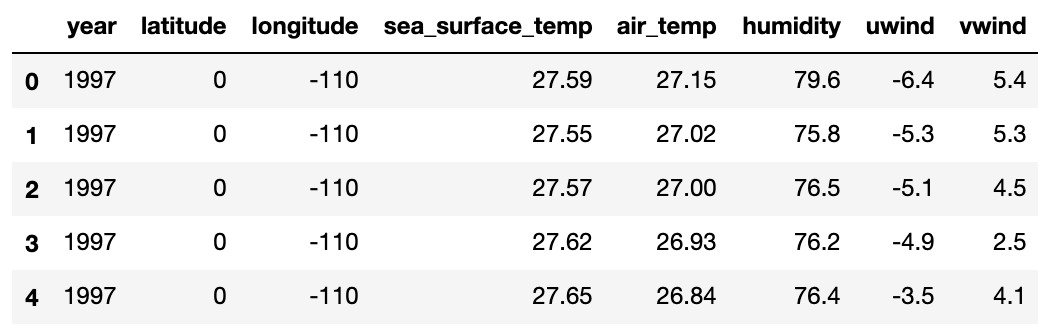
A quick look at the data frame tells us there is a substantial number of missing values in the air_temp variable, which we will need to impute before modeling.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 733 entries, 0 to 732
Data columns (total 8 columns):
year 733 non-null int64
latitude 733 non-null int64
longitude 733 non-null int64
sea_surface_temp 733 non-null float64
air_temp 655 non-null float64
humidity 642 non-null float64
uwind 733 non-null float64
vwind 733 non-null float64
dtypes: float64(5), int64(3)
memory usage: 45.9 KB
Scikit-learn offers imputing transformers such as SimpleImputer which fills-in the variable’s missing values by its mean, median, or some other quantity. However, such imputation is known to destroy relations in the data.
But look, there is another variable called sea_surface_temp with no missing values! We could expect the water temperature to be highly correlated with air temperature! Let’s plot these two variables against each other.
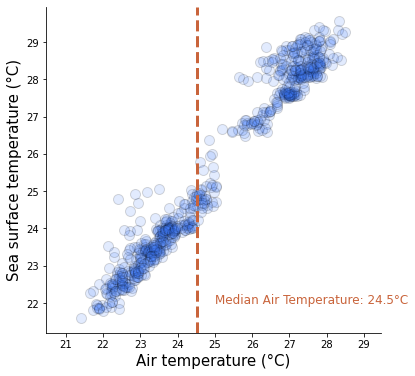
As we expected, there is a clear linear relationship. Also, we can see why mean or median imputation makes no sense: setting air temperature to its median value of 24.5 degrees for observations where the water temperature is 22 or 29 completely destroys the relation between these two variables.
It seems that a good strategy for imputing air_temp would be to use linear regression with sea_surface_temp as a predictor. As of scikit-learn version 0.21, we can use the IterativeImputer and set LinearRegression as the imputing engine. However, this will use all the variables in the data as predictors, while we only want the water temperature. Let’s write our own transformer to achieve this.
A custom transformer
A scikit-learn transformer should be a class implementing three methods:
fit(), which simply returnsself,transform(), which takes the dataXas input and performs the desired transformations,fit_transform(), which is added automatically if you includeTransformerMixinas a base class.
On top of these, we have the __init__() to capture the parameters - in our example the indices of air and water temperature columns. We can also include BaseEstimator as a base class, which will allow us to retrieve the parameters from the transformer object.
#software-development #python #machine-learning #scikit-learn #data-science #deep learning
