This blog is an abridged version of the talk that I gave at the Apache Ignite community meetup. You can download the slides that I presented at the meetup here. In the talk, I explain how data in Apache Ignite is distributed.
Why Do You Need to Distribute Anything at all?
Inevitably, the evolution of a system that requires data storage and processing reaches a threshold. Either too much data is accumulated, so the data simply does not fit into the storage device, or the load increases so rapidly that a single server cannot manage the number of queries. Both scenarios happen frequently.
Usually, in such situations, two solutions come in handy—sharding the data storage or migrating to a distributed database. The solutions have features in common. The most frequently used feature uses a set of nodes to manage data. Throughout this post, I will refer to the set of nodes as “topology.”
The problem of data distribution among the nodes of the topology can be described in regard to the set of requirements that the distribution must comply with:
- Algorithm. The algorithm allows the topology nodes and front-end applications to discover unambiguously on which node or nodes an object (or key) is located.
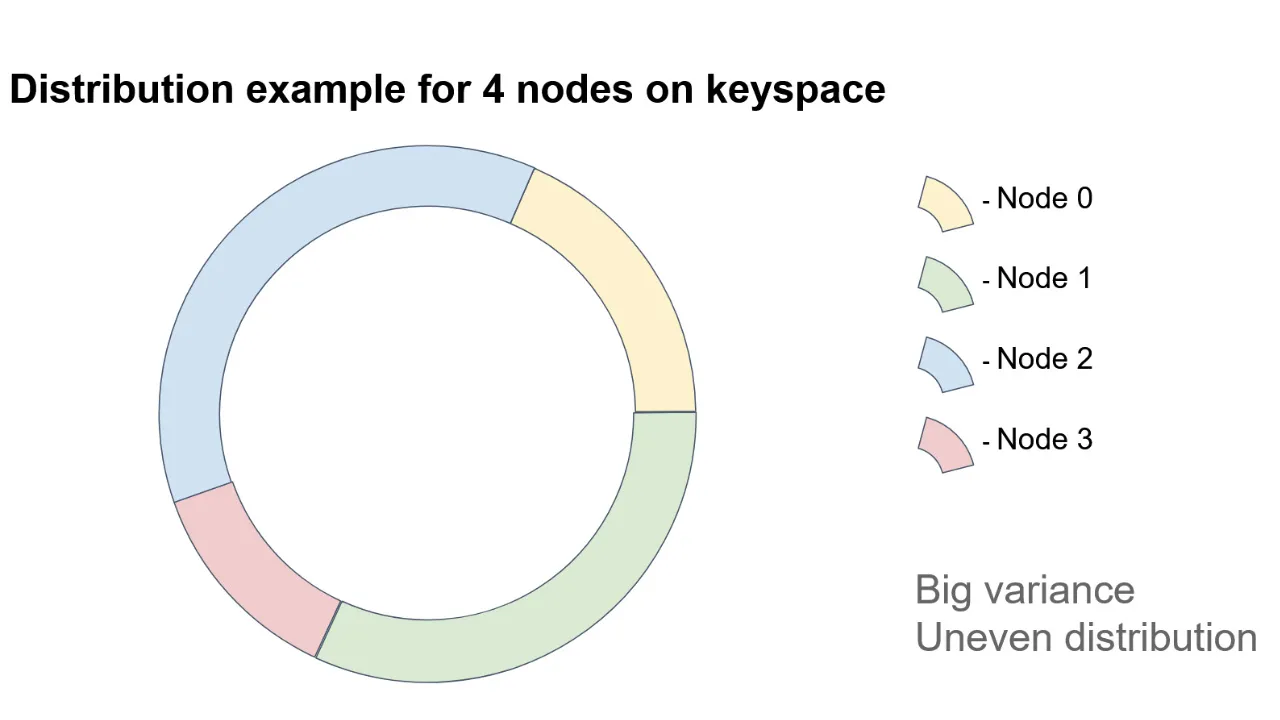
- Distribution uniformity. The more uniform the data distribution is among the nodes, the more uniform the workloads on the nodes is. Here, I assume that the nodes have approximately equal resources.
- Minimal disruption. If the topology is changed because of a node failure, the changes in distribution should affect only the data that is on the failed node. It should also be noted that, if a node is added to the topology, no data swap should occur among the nodes that are already present in the topology.
#tutorial #big data #distributed systems #apache ignite #distributed storage #data distribution #consistent hashing