With the advancement of technology, we are(or are rather slowly) moving from industrial sector to service sector. Which means it becomes an imminent part of our life to continuously review what we are offering to our customers and how they are perceiving our products. Nevertheless, with everybody who have access to internet, and advocates free will and freedom of speech is entitled to praise or loathe a service they receive via voicing their opinions.
Inline to make a better experience for our customers or clients, it becomes inevitable for an organization to analyze their decisions. It will be arduous to read surplus of reviews, testimonies, etc to understand how the service is doing ? or perhaps understand how products are doing in the market? or perhaps How are customers reacting to a particular product? or maybe What is the consumer’s sentiment across products? Many more questions like these can be answered using sentiment analysis.
In this article we will touch base with
WordClouds
Sentiment Analysis
About Data set :
'''
Getting the data
'''
# importing All the necessary libraries for working with the data
import numpy as np # For numerical processing
import pandas as pd # working with the dataframes
import matplotlib.pyplot as plt # nice looking plots
%matplotlib inline
# #Read the data
df = pd.read_csv('Reviews.csv')
df.info()
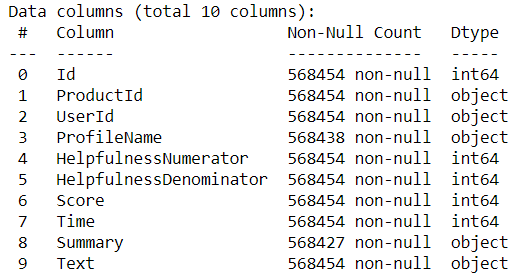
df.info() output
- I am using the Amazon’s fine food reviews which can be available to you from here.
- The attributes we have here are — productID, userID, score( which loosely translates into star rating), summary, text(their review), etc.
- We observe that there are missing details in ProfileName and Summary attributes.
Natural Language Processing starts here where we load libraries and work with the data
# Import libraries
from nltk.corpus import stopwords
from textblob import TextBlob
from textblob import Word
Stop words
StopWords are basically a set of commonly used words in any language, not just English. The reason why stop words are critical to many applications is that, if we remove the words that are very commonly used in a given language, we can focus on the important words instead. Examples of minimal stop word lists that you can use:
Determiners_ — Determiners tend to mark nouns where a determiner usually will be followed by a noun_
examples: the, a, an, another
_Coordinating conjunctions _— Coordinating conjunctions connect words, phrases, and clauses
examples: for, an, nor, but, or, yet, so
Prepositions_ — Prepositions express temporal or spatial relations_
examples: in, under, towards, before
TextBlob
TextBlob is a Python (2 and 3) library for processing textual data. It provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
After importing the libraries, we shall remove StopWords and Punctuations, because they can heavily influence data and belie the accuracy. Additionally, we have to make all the words into similar textual casing i.e, lower.
# Lower Casing
df['Text'] = df['Text'].apply(lambda x: " ".join(x.lower() for x in x.split()))
# Removing Punctuations
df['Text'] = df['Text'].str.replace('[^\w\s]','')
# Removal of Stop Words
stop = stopwords.words('english')
df['Text'] = df['Text'].apply(lambda x: " ".join(x for x in x.split() if x not in stop))
#sentiment-analysis #machine-learning #data-science #word-cloud #data analysis