Optimizer is a technique that we use to minimize the loss or increase the accuracy. We do that by finding the local minima of the cost function.
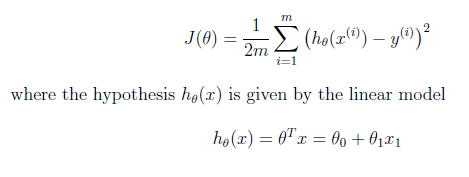
Our parameters are updated like this:
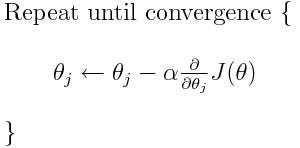
When our cost function is convex in nature having only one minima which is its global minima. We can simply use Gradient descent optimization technique and that will converge to global minima after a little tuning in hyper-parameters.

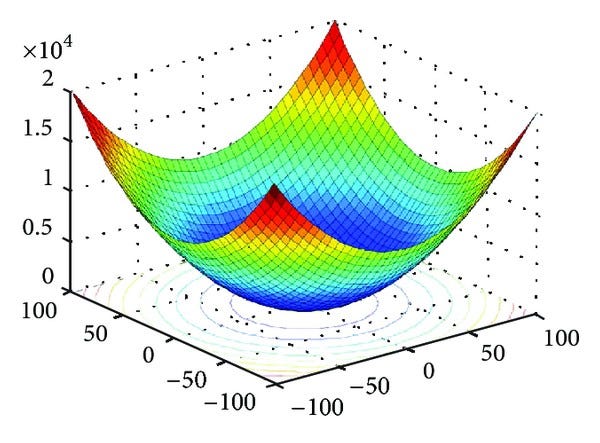
But in real world problems the cost function has lots of local minima. And the Gradient Descent technique fails here and we can end up in local minima instead of global minima.
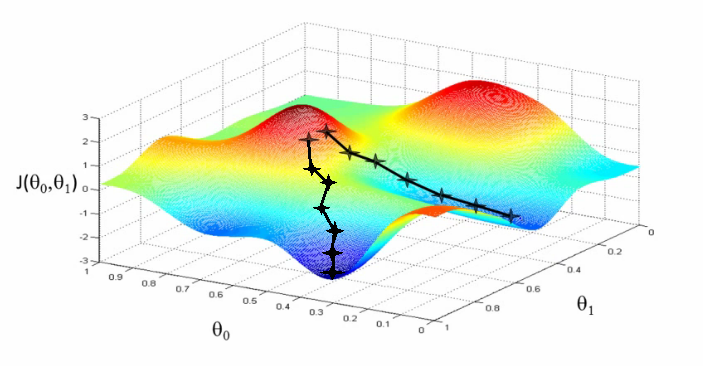
So, to save our model from getting stuck in local minima we use an advanced version of Gradient Descent in which we use the momentum.
Imagine a ball, we started from some point and then the ball goes in the direction of downhill or descent. If the ball has the sufficient momentum than the ball will escape from the well or local minima in our cost function graph.
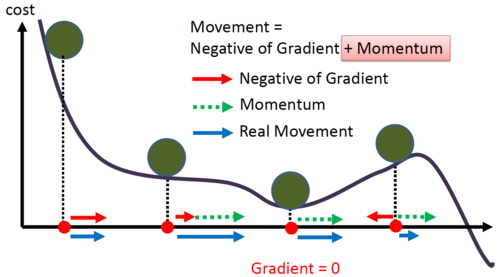
Gradient Descent with Momentum considers the past gradients to smooth out the update. It computes an exponentially weighted average of your gradients, and then use that gradient to update the weights.
#neural-networks #deep-learning #optimization-algorithms #algorithms