Node.js is a JavaScript runtime environment built on Chrome’s V8 JavaScript engine, it implements the reactor pattern, a non-blocking, event-driven I/O paradigm.
You definitely don’t want to use Node.js for CPU-intensive operations, using it for heavy computation will annul nearly all of its advantages. Node.js really shines in building fast, scalable network applications, as it’s capable of handling a huge number of simultaneous connections with high throughput.
One way to improve the throughput of a web application is to scale it, instantiate it multiple times balancing the incoming connection between the multiple instances, so this first article will be about how to horizontally scale a Node.js application, on multiple cores or on multiple machines.
When you scale up, you have to be careful about different aspects of your application, from the state to the authentication, so the second article will cover some** things you must consider** when scaling up a Node.js application.
Over the mandatories ones, there are some good practices you can addressthat will be covered in the third article, like splitting api and worker processes, the adoption of priority queues, the management of periodic jobs like cron processes, that are not intended to run N times when you scale up to N processes/machines.
1. Serve static from Node.js in dev, serve it from a CDN in prod

I wish I saw companies make this mistake less often. Serving your static assets from your web application (particularly through something like webpack-dev-server or Parcel’s dev server) is a great developer experience since it shortens the feedback loop when you’re writing code. However you should never serve your static assets via Node.js. They should be compiled separately and served via CDN, like Azure CDN. Serving it from Node.js is unnecessarily slow since CDNs are more dispersed and therefore normally physically closer to the end user and CDN servers are highly optimized for server small assets. Serving assets from Node is also unnecessarily expensive since Node.js server time is far more expensive than CDN server time.
In a classic web app the backend serves the frontend/graphics to the browser, a very common approach in the Node’s world is to use Express static middleware for streamlining staitc files to the client. BUT – Node is not a typical webapp as it utilizes a single thread that is not optimized to serve many files at once. Instead, consider using a reverse proxy, cloud storage or CDN (e.g. Nginx, AWS S3, Azure Blob Storage, etc) that utilizes many optimizations for this task and gain much better throughput. For example, specializes middleware like nginx embodies direct hook between the file system and the network card and multi-thread approach to minimize intervention among multiple request.
Your optimal solution might wear one of the following forms:
(1) A reverse proxy – your static files will be located right next to your Node application, only requests to the static files folder will be served by a proxy that sits in front of your Node app such as nginx. Using this approach, your Node app is responsible deploying the static files but not to serve them. Your frontend’s colleague will love this approach as it prevents cross-origin-requests from the frontend
(2) Cloud storage – your static files will NOT be part of your Node app content, else they will be uploaded to services like AWS S3, Azure BlobStorage, or other similar services that were born for this mission. Using this approach, your Node app is not responsible deploying the static files neither to serve them, hence a complete decoupling is drawn between Node and the Frontend which is any way handled by different teams
2. Microservices and containers at scale
_A microservice is a single self-contained unit which, together with many others, makes up a large application. By splitting your app into small units every part of it is independently deployable and scalable, can be written by different teams and in different programming languages and can be tested individually. — _Max Stoiber
_A microservice architecture means that your app is made up of lots of smaller, independent applications capable of running in their own memory space and scaling independently from each other across potentially many separate machines. — _Eric Elliot
The benefits of microservices
- The application starts faster, which makes developers more productive, and speeds up deployments.
- Each service can be deployed independently of other services — easier to deploy new versions of services frequently
- Easier to scale development and can also have performance advantages.
- Eliminates any long-term commitment to a technology stack. When developing a new service you can pick a new technology stack.
- Microservices are typically better organized, since each microservice has a very specific job, and is not concerned with the jobs of other components.
- Decoupled services are also easier to recompose and reconfigure to serve the purposes of different apps (for example, serving both the web clients and public API).
The drawbacks of microservices
- Developers must deal with the additional complexity of creating a distributed system.
- Deployment complexity. In production, there is also the operational complexity of deploying and managing a system comprised of many different service types.
- As you’re building a new microservice architecture, you’re likely to discover lots of cross-cutting concerns that you did not anticipate at design time.
Architecture for your microservice
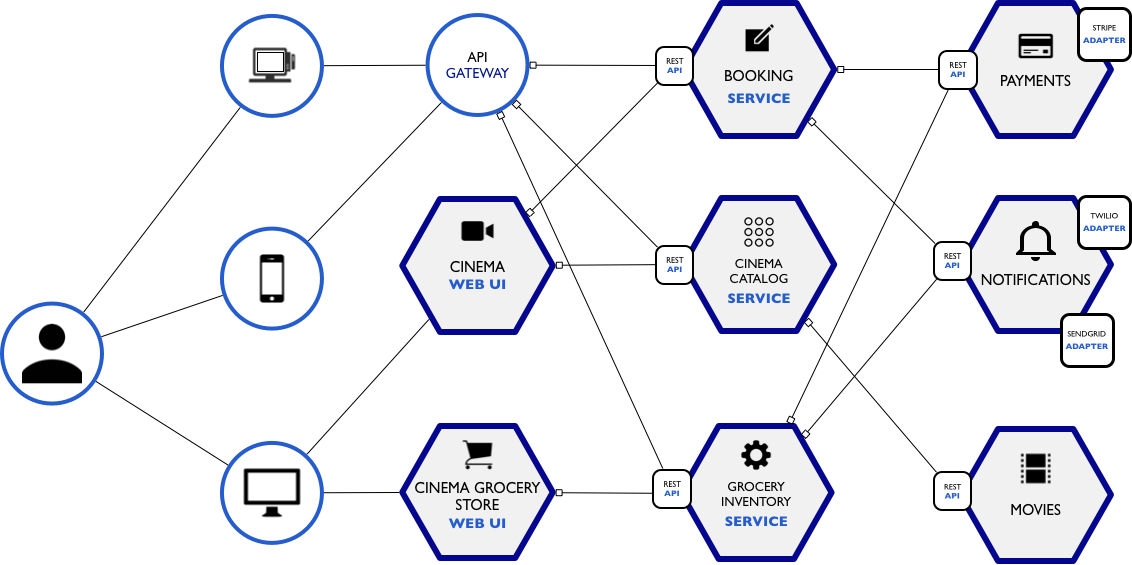
**Cinema Microservice Example**
Let’s imagine that we are woking in the IT department of Cinépolis (A Mexican cinema), and they give us the task of restructuring their tickets and grocery store from a monolithic system to a microservice.
3. Multiple processes on same machine
The real key to high – that is, nearly unlimited – performance for Node.js applications is to run multiple application servers and balance loads across all of them.
Node.js load balancing can be particularly tricky because Node.js enables a high level of interaction between JavaScript code running in the web browser and JavaScript code running on the Node.js application server, with JSON objects as the medium of data exchange. This implies that a given client session runs continually on a specific application server, and session persistence is inherently difficult to achieve with multiple application servers.
One of the major advantages of the Internet and the web are their high degree of statelessness, which includes the ability for client requests to be fulfilled by any server with access to a requested file. Node.js subverts statelessness and works best in a stateful environment, where the same server consistently responds to requests from any specific clients. you can read more about it here
4. Enter the _cluster _module
To take advantage of multi-core systems, you will have to launch a “cluster” of Node.js processes to handle the load. Luckily, the Node.js API has a module called cluster. This module allows for the easy creation of child processes that all share server ports. You can find it’s documentation here.
Take a look at the simplest possible example of a working cluster straight from Node.js documentation:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
}
It’s a great starter, but there’s one fundamental problem with this bit of code. If one of your child processes dies, it never spawns back. That’s not a major issue, though, and we can solve it with simple trick. Let’s add the following piece of code inside the if (cluster.isMaster) statement:
cluster.on('exit', (worker, code, signal) => {
cluster.fork();
});
Great! Now, each time one of your nodes dies, it simply gets respawned by master – regardless of whether it was because of an uncaught exception, an out-of-memory exception, or because someone explicitly killed that process.
Unfortunately, there’s a problem with this small improvement. Image there’s a small bug inside your process initialization code or just a typo, something like this, for instance: conso**el**.log(“There\’s a typo here!”);
What would happen here would be something like a controlled semi-forkbomb. Your processes would keep starting and dying immediately. Because would they disappear, the master would try to spawn new processes, but they would also die immediately. Welcome to an infinite loop of forks and unexpected process exits.
Actually, there are many cases like the one above. If you try to handle them all, you’ll spend a non-trivial amount of time writing your own process manager, and at the end of the day, it isn’t going to be perfect anyway. Congrats! You’ve just wasted a day of work, while you could have closed 3 tickets instead and bring some business value.
5. Constantly Analyze Test Results and Engine Health
When load testing, two of the most important health parameters we look at are CPU and memory usages of our website. You need to determine the usage levels that you don’t want your system to cross, but if you reach 75% CPU and 85% memory, you’re approaching a red line that you don’t want to cross.
To monitor your system’s health, look at the reports the load testing systems offer and analyze different KPIsand the correlations between them. CA BlazeMeter offers an Engine Health report, but you can also analyze these parameters on Taurus, an open-source test automation tool.

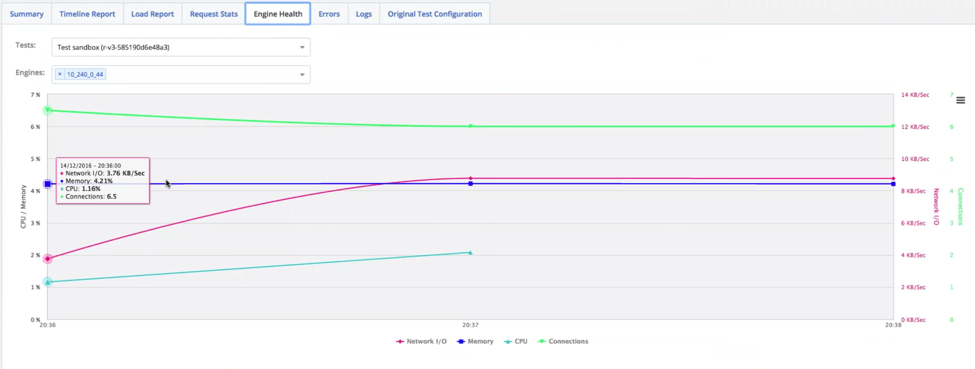
It’s important to analyze the results in real-time after every test you run and over time. This ensures that you get a full picture of your system’s abilities, weaknesses, and bottlenecks. They also let you see what happens to your system when changing it, like adding features or changing the system’s architecture. Finally, they let you see if the fixes you’ve made are really helping.
Ensuring your system handles heavy loads is important for keeping users and customers coming. We hope these tips will help you when scaling to high numbers.
Originally published at https://socialdribbler.com/how-do-you-scale-node-js-apis/
Learn More
☞ The Complete Node.js Developer Course (2nd Edition)
☞ GraphQL: Learning GraphQL with Node.Js
☞ Angular (Angular 2+) & NodeJS - The MEAN Stack Guide
☞ Beginner Full Stack Web Development: HTML, CSS, React & Node
☞ Node with React: Fullstack Web Development
☞ MERN Stack Front To Back: Full Stack React, Redux & Node.js
☞ Building MongoDB Dashboard using Node.js
☞ Run your Node.js application on a headless Raspberry Pi
#node-js #api
