It goes without saying that if you want to orchestrate containers at this point, Kubernetes is what you use to do it. Sure, there may be a few Docker Swarm holdouts still around, but for the most part, K8s has cemented itself as the industry standard for container orchestration solutions. As Kubernetes matures, the tools that embody its landscape begin to mature along with it. One of the areas we have seen some optimization, in particular, is in cloud-native storage solutions.
What is Rook?
Rook is an open-source cloud-native storage orchestrator, providing the platform, framework, and support for a diverse set of storage solutions to natively integrate with cloud-native environments.
It turns storage software into self-managing, self-scaling, and self-healing storage services. It does this by automating deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management. Rook uses the facilities provided by the underlying cloud-native container management, scheduling, and orchestration platform to perform its duties. It supports a variety of different block, **object, **and file type storage.
Rook integrates deeply into cloud-native environments leveraging extension points and providing a seamless experience for scheduling, lifecycle management, resource management, security, monitoring, and user experience.
What is Ceph?
Ceph is a distributed storage system that is massively scalable and high-performing with no single point of failure. Ceph is a Software Distributed System (SDS), meaning it can be run on any hardware that matches its requirements.
Ceph consists of multiple components:
- **Ceph Monitors (MON) **are responsible for forming cluster quorums. All the cluster nodes report to monitor nodes and share information about every change in their state.
- Ceph Object Store Devices (OSD) are responsible for storing objects on local file systems and providing access to them over the network. Usually, one OSD daemon is tied to one physical disk in your cluster. Ceph clients interact with OSDs directly.
- Ceph Manager (MGR) provides additional monitoring and interfaces to external monitoring and management systems.
- Reliable Autonomic Distributed Object Stores (RADOS) are at the core of Ceph storage clusters. This layer makes sure that stored data always remains consistent and performs data replication, failure detection, and recovery among others.
To read/write data from/to a Ceph cluster, a client will first contact Ceph MONs to obtain the most recent copy of their cluster map. The cluster map contains the cluster topology as well as the data storage locations. Ceph clients use the cluster map to figure out which OSD to interact with and initiate a connection with the associated OSD.
Rook enables Ceph storage systems to run on Kubernetes using Kubernetes primitives. The following image illustrates how Ceph Rook integrates with Kubernetes:
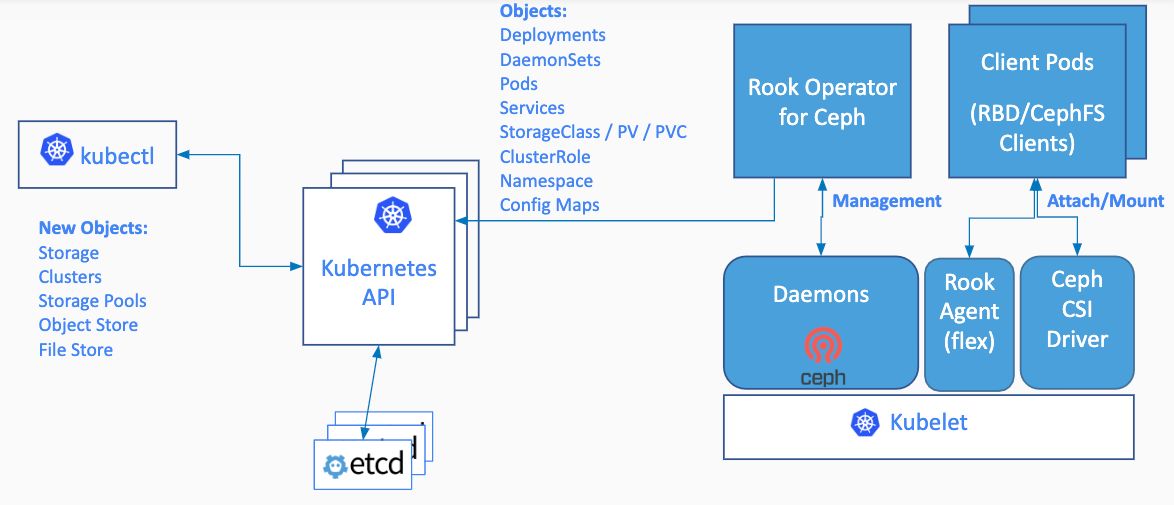
The Rook operator is a simple container that has all that is needed to bootstrap and monitor the storage cluster. The operator will start and monitor Ceph monitor pods, the Ceph OSD daemons to provide RADOS storage, as well as start and manage other Ceph daemons. The operator manages CRDs for pools, object stores (S3/Swift), and filesystems by initializing the pods and other artifacts necessary to run the services.
The operator will monitor the storage daemons to ensure the cluster is healthy. Ceph mons will be started or failed over when necessary, and other adjustments are made as the cluster grows or shrinks. The operator will also watch for desired state changes requested by the api service and apply the changes.
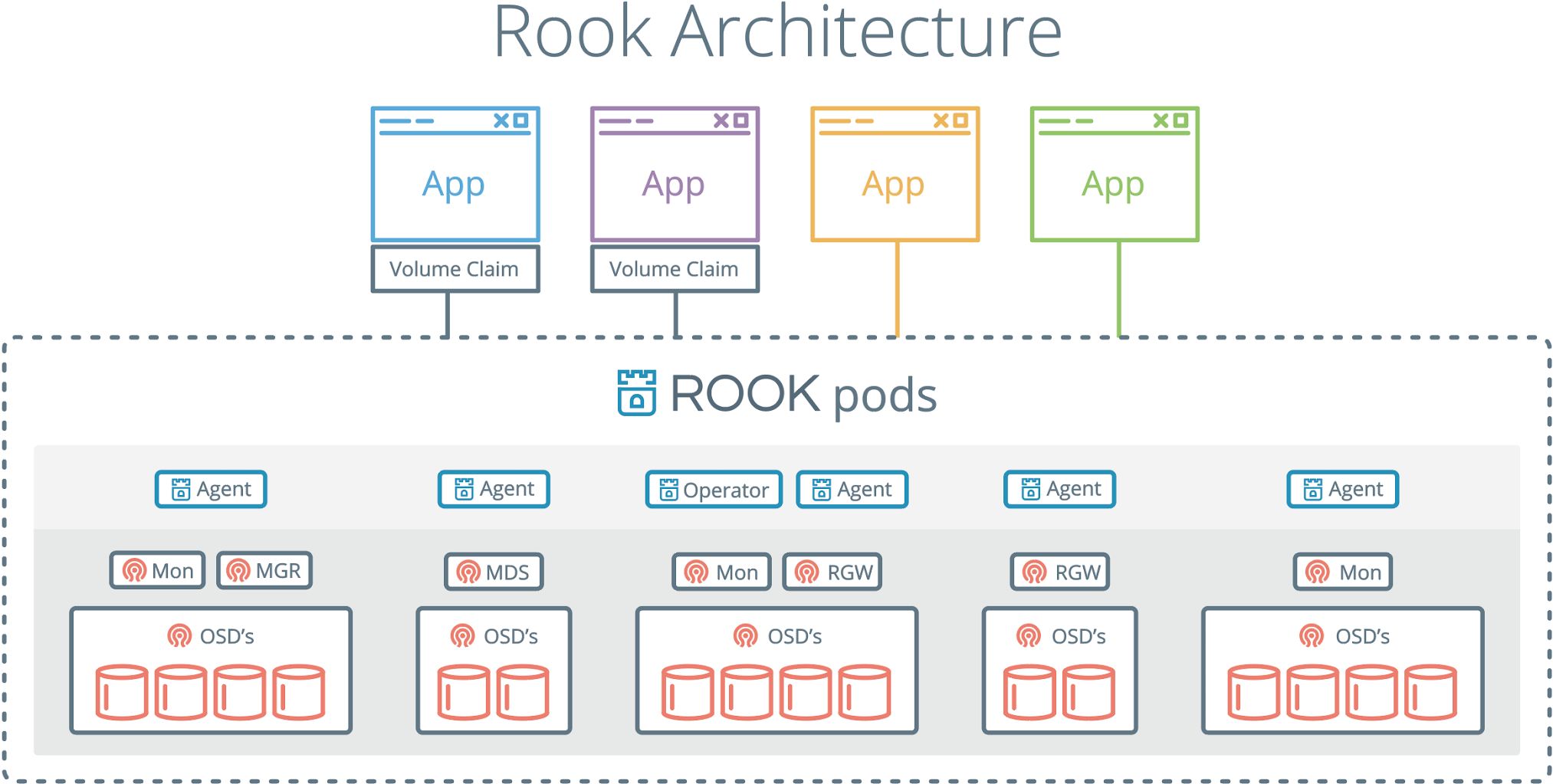
The rook/ceph image includes all necessary tools to manage the cluster – there are no changes to the data path. Rook does not attempt to maintain full fidelity with Ceph. Many of the Ceph concepts like placement groups and crush maps are hidden so you don’t have to worry about them. Instead, Rook creates a much simplified UX for admins that is in terms of physical resources, pools, volumes, filesystems, and buckets. At the same time, an advanced configuration can be applied when needed with the Ceph tools.
Rook is implemented in Golang. Ceph is implemented in C++ where the data path is highly optimized. We believe this combination offers the best of both worlds.
#cloud-computing #cloud-native #cloud
![How To Deploy A Scalable Cloud Storage Using Rook And Ceph Storage [Part 1]](https://firebasestorage.googleapis.com/v0/b/hackernoon-app.appspot.com/o/images%2FkaGFDumlYXRgWiJ4IylKb6uaYLs1-y58y3uts.jpeg?alt=media&token=41fe04d3-75a0-456e-8bb7-ff8f91dd3b2b)