Optimization refers to the task of minimizing/maximizing an objective function f(x) parameterized by x. In machine/deep learning terminology, it’s the task of minimizing the cost/loss function J(w) parameterized by the model’s parameters w ∈ R^d.
Optimization algorithms (in the case of minimization) have one of the following goals:
- Find the global minimum of the objective function. This is feasible if the objective function is convex, i.e. any local minimum is a global minimum.
- Find the lowest possible value of the objective function within its neighborhood. That’s usually the case if the objective function is not convex as the case in most deep learning problems.
Gradient Descent
Gradient Descent is an optimizing algorithm used in Machine/ Deep Learning algorithms. The goal of Gradient Descent is to minimize the objective convex function f(x) using iteration.

Convex function v/s Not Convex function
Let’s see how Gradient Descent actually works by implementing it on a cost function.
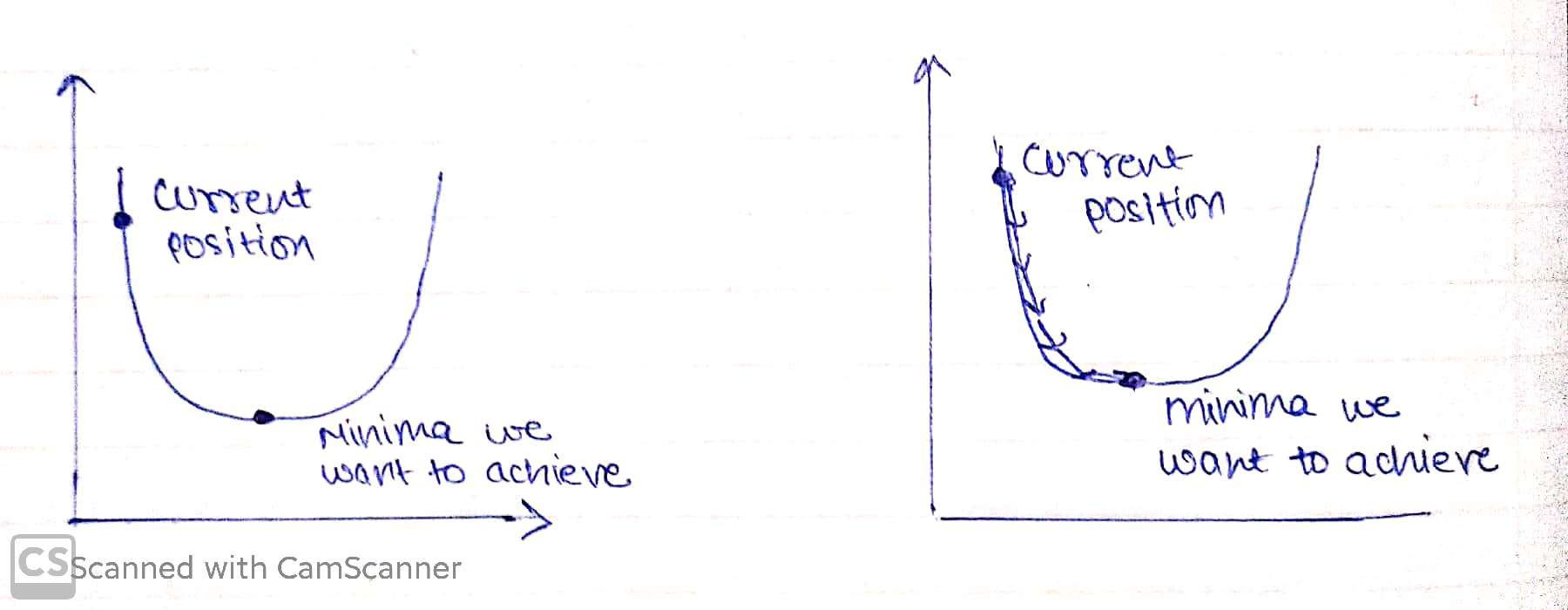
Intuition behind Gradient Descent
For ease, let’s take a simple linear model.
Error = Y(Predicted)-Y(Actual)
A machine learning model always wants low error with maximum accuracy, in order to decrease error we will intuit our algorithm that you’re doing something wrong that is needed to be rectified, that would be done through Gradient Descent.
We need to minimize our error, in order to get pointer to minima we need to walk some steps that are known as alpha(learning rate).
Steps to implement Gradient Descent
- Randomly initialize values.
- Update values.

3. Repeat until slope =0
A derivative is a term that comes from calculus and is calculated as the slope of the graph at a particular point. The slope is described by drawing a tangent line to the graph at the point. So, if we are able to compute this tangent line, we might be able to compute the desired direction to reach the minima.
Learning rate must be chosen wisely as:
1. if it is too small, then the model will take some time to learn.
2. if it is too large, model will converge as our pointer will shoot and we’ll not be able to get to minima.

Big Learning rate v/s Small Learning rate, Source

Gradient Descent with different learning rates, Source
Vanilla gradient descent, however, can’t guarantee good convergence, due to following reasons:
- Picking an appropriate learning rate can be troublesome. A learning rate that is too low will lead to slow training and a higher learning rate will lead to overshooting of slope.
- Another key hurdle faced by Vanilla Gradient Descent is it avoid getting trapped in local minima; these local minimas are surrounded by hills of same error, which makes it really hard for vanilla Gradient Descent to escape it.

Contour maps visualizing gentle and steep region of curve, Source
In simple words, every step we take towards minima tends to decrease our slope, now if we visualize, in steep region of curve derivative is going to be large therefore steps taken by our model too would be large but as we will enter gentle region of slope our derivative will decrease and so will the time to reach minima.
#gradient-descent #optimization #data-science #data analysis
