One-hot encoding, otherwise known as dummy variables, is a method of converting categorical variables into several binary columns, where a 1 indicates the presence of that row belonging to that category.
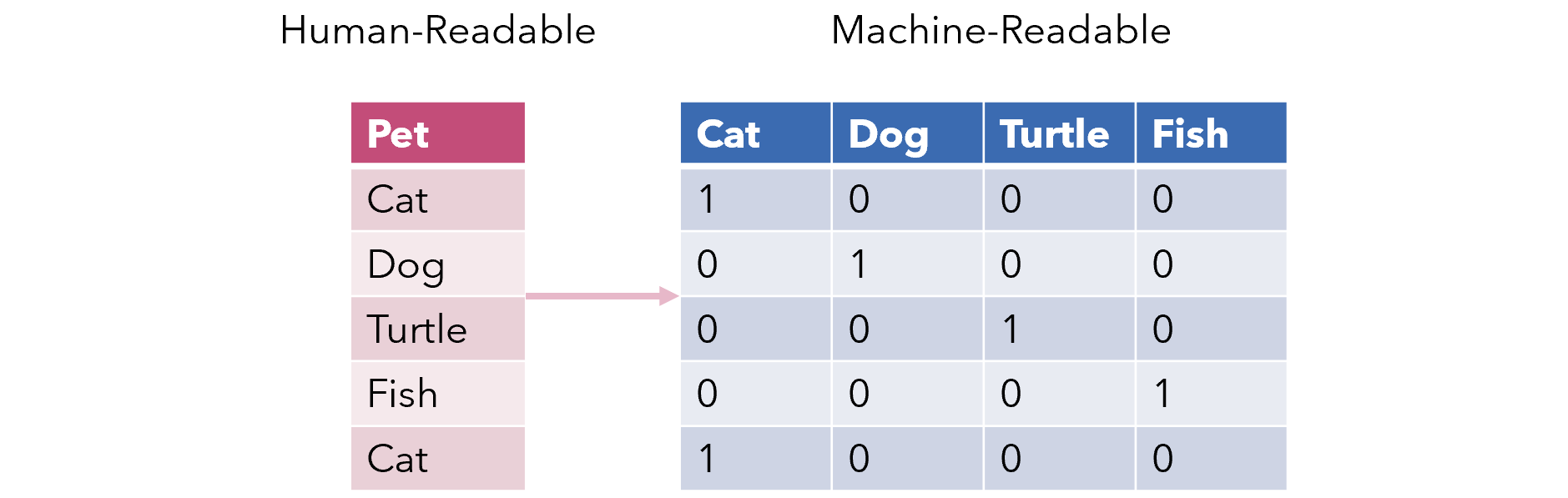
It is, pretty obviously, not a great a choice for the encoding of categorical variables from a machine learning perspective.
Most apparent is the heavy amount of dimensionality it adds, and it is common knowledge that generally a lower amount of dimensions is better. For example, if we were to have a column representing a US state (e.g. California, New York), a one-hot encoding scheme would result in fifty additional dimensions.
Not only does it add a massive number of dimensions to the dataset, there really isn’t much information — ones occasionally dotting a sea of zeroes. This results in an exceptionally sparse landscape, which makes it hard to grapple with optimization. This is especially true with neural networks, whose optimizers have enough trouble navigating the error space without dozens of empty dimensions.
Worse, each of the information-sparse columns have a linear relationship with each other. This means that one variable can be easily predicted using the others, can causes problems of parallelism and multicollinearity in high dimensions.

The optimal dataset consists of features whose information is independently valuable, and one-hot encoding creates an environment of anything but that.
Granted, if there are only three or perhaps even four classes, one-hot encoding may not be that bad a choice, but chances are it’s worth exploring the alternatives, depending on the relative size of the dataset
#data-analysis #machine-learning #data #data-science #artificial-intelligence
