還記得之前在評估模型的好壞時,MSE是怎麼算的嗎?是要用真實情況(test)的結果去和預測比對,但是我們一直以來都是用validation data,畢竟真正的testing data要等事情已經發生完了,才能事後檢查模型的好壞。
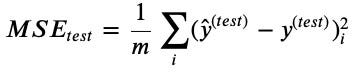
除了MSE,大家還記得機器學習的最終任務嗎?
機器學習的任務:於可及範圍的 H中挑選一個與 f最相似的 h
但是 h 與 f 終究是不同的函數,而我們關心的是 𝑦̂ 與 y 間的差異,差異小的h稱為**泛化(Generalization)**的能力好
h的誤差可能源於 Training error 與 Test error:
Training error 常被稱為 error或 bias
Test error 亦可被稱為 Generalization error, 被簡稱為 variance
如果太過度注重 training data,擴增回歸模型的可及範圍H常伴隨 error 降低,但variance提高。因此機器學習的另一非常重要的任務就是要找平衡。我們試著在回歸模型中分別加入高次項(從1-10次方),分別看Training error 與 Test data 的大小:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
nba_data = pd.read_csv('/Users/changyucheng/Desktop/Medium/nba_players.csv')
X = nba_data['ppg'].values.reshape(-1, 1)
degrees = range(1, 11)
training_errors = []
test_errors = []
for deg in degrees:
poly = PolynomialFeatures(degree = deg)
X_poly = poly.fit_transform(X)
y = nba_data['salary'].values
X_train, X_validation, y_train, y_validation = train_test_split(X_poly, y, test_size = 0.33, random_state = 42)
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_train)
training_err = mean_squared_error(y_train, y_pred)
training_errors.append(training_err)
y_pred = lr.predict(X_validation)
test_err = mean_squared_error(y_validation, y_pred)
test_errors.append(test_err)
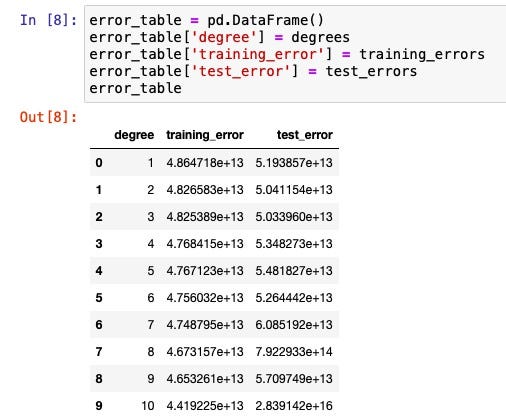
回歸模型 fit 完10次了之後,Training error這個list裡會有10筆資料,是X_train丟到模型h裡,預測出來的值(y_pred)和y_train的差距。可以看到隨著次方越來越高,Training error是越來越小的。
接著看Test error:在前幾次分別加入二次項、三次項,error是有往下降一點,但是隨著加入的次方提高,越到後面error開始飆高。這說明如果模型太複雜,即使 training data 丟到模型裡表現很完美,但是一旦丟testing data,模型的預測結果會非常不準。
#python #機器學習 #machine-learning