Table of Content:
- Introduction
- Data Validation
- Model validation
- Summary
1. Introduction
“All models are wrong, but some are useful.” — George Box.
To build a solution using Machine Learning (ML) is a complex task by itself. Whilst academic ML has its roots in research from the 1980s, the practical implementation of Machine Learning Systems in production is still relatively new.
Today I would like to share some ideas on how to make your ML Pipelines robust and interpretable using Apache Airflow. The whole project is available on Github. The code is dockerized, so it’s pretty straightforward to play around with it even if you are not familiar with the technology.
The topic is complex and multifaceted. In this article, I would like to focus only on the two parts of any ML project — Data Validation and Model Evaluation. The goal is to share practical ideas, that you can introduce in your project relatively simple, but still achieve great benefits.
The subject is very extensive, so let’s introduce several restrictions:
- We gonna use Apache Airflow as a pipeline orchestration tool;
- We will consider a ML training pipeline.
- We will focus on the practical things that common for most projects.
If you are not familiar with Airflow, it is a platform to programmatically author, schedule, and monitor workflows [1]. Airflow workflows are built as Directed Acyclic Graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. The command-line utilities make performing complex surgeries on DAGs a snap. The user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
2. Data Validation
Data Validation is the process of ensuring that data is present, correct, and meaningful. Ensuring the quality of your data through automated validation checks is a critical step in building data pipelines at any organization.
The data validation step is required before model training to decide whether you could train the model or stop the execution of the pipeline. This decision is automatically made if the following was identified by the pipeline [2]:
- Data schema skews: these skews are considered anomalies in the input data, which means that the downstream pipeline steps, including data processing and model training, receive data that doesn’t comply with the expected schema. Schema skews include receiving unexpected features, not receiving all the expected features, or receiving features with unexpected values.
- Data values skew: these skews are significant changes in the statistical properties of data, which means that data patterns are significantly changed, and you need to check the nature of these changes.
Importance of the data validation:
- The quality of the model depends on the quality of the data.
- Increasing confidence in data quality by quantifying data quality.
- Correcting the trained ML model can be expensive — prevent is better than cure.
- Stopping training a new ML model if the data is invalid.
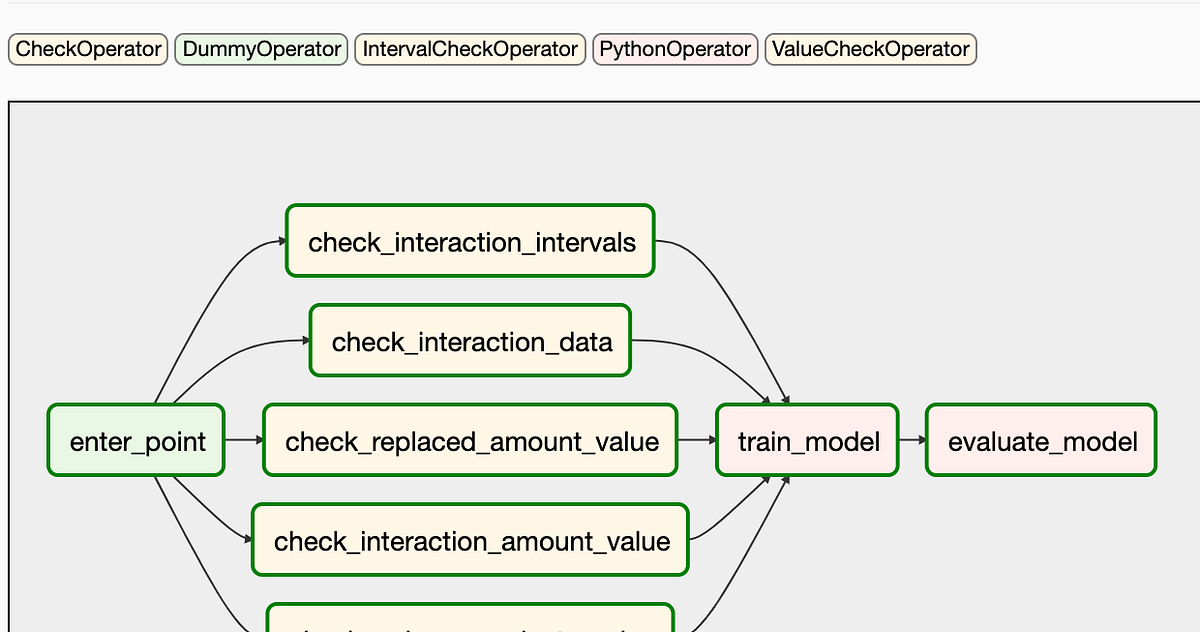
Airflow provides a group of check operators, that allows us easy verify data quality. Let’s look at how to use such Operators on practical examples.
#data-science #data-engineering #airflow #data-pipeline #data analysis