In the first series of this article, we discussed what feature selection is about and provided some walkthroughs using the statistical method. This article follow-ups on the original article by further explaining the other two common approaches in feature selection for Machine Learning (ML) — namely the wrapper and embedded methods. Explanations will be accompanied by sample coding in Python.
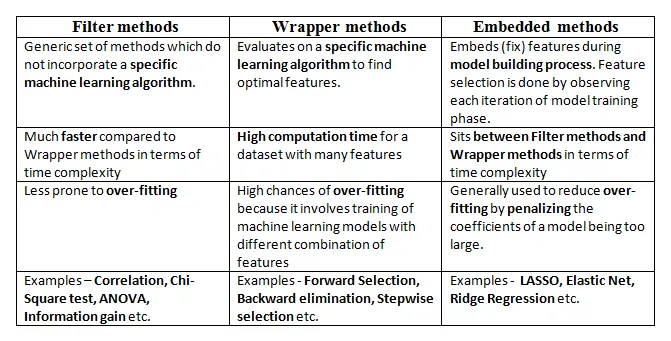
To recap, feature selection means to reduce the number of predictors used to train a ML model. The main goals are to improve the accuracy of the predictive performance (by reducing the number of redundant predictors), reduce calculation time (fewer predictors, less time needed to compute), and to improve the interpretability of the model (easier to study the dependency of predictors when the number is smaller). Filter method, which is based on statistical technique can be generally applied independently of the algorithms used for a ML model. However, wrapper and embedded methods are normally “fine-tuned” to optimize the classifier performance, making them ideal if the goal is to objectively find out an ideal set of predictors for a specific learning algorithm or model.
Introduction and Concept
Wrapper methods_ evaluate multiple models using procedures that add and/or remove predictors to find the optimal combination that maximizes model performance. [1] These procedures are normally built after the concept of Greedy Search technique (or algorithm). [2] A greedy algorithm is any algorithm that follows the problem-solving heuristic of making the locally optimal choice at each stage.[3]_
Generally, three directions of procedures are possible:
- Forward selection — starts with one predictor and adds more iteratively. At each subsequent iteration, the best of the remaining original predictors are added based on performance criteria.
- Backward elimination — starts with all predictors and eliminates one-by-one iteratively. One of the most popular algorithms is Recursive Feature Elimination (RFE) which eliminates less important predictors based on feature importance ranking.
- Step-wise selection — bi-directional, based on a combination of forward selection and backward elimination. It is considered less greedy than the previous two procedures since it does reconsider adding predictors back into the model that has been removed (and vice versa). Nonetheless, the considerations are still made based on local optimisation at any given iteration.
#programming #python #machine-learning #feature-selection #data-science