Databases are an important part of (almost) every piece of software today. In this article I’m going to tell you everything you need to know to start working with them.
What is a database?
If you manage information in files or folders, you sooner or later will find that:
- You have multiple files that contain the same information
- You have multiple files about the same topic but with different information, making difficult to understand which file has the correct/updated information.
- Every time you want to change some information you have to update multiple files, taking a lot of time and potentially making mistakes that lead to the two previous problems.
This approach for handling information is inefficient, databases were made to fix these problems.
A Database is a system that allows everyone to share, manage and use data. To use one you first need to understand some things:
- A lot of people will be using it, so you have to find a way for them to easily input and extract data.
- Databases also present risks like users stealing or overwriting important information, so security and permissions should be taken into consideration when designing a database.
- You also need to be careful not to lose any data. The system may go down or a hard drive can fail. Databases need mechanisms to recover from this failures.
Types of databases
There are many kinds of databases, these three are the most commonly used data models for databases:
- Hierarchical Data Model, in which there is a tree-like relationship between data.
- Network Data Model, in which pieces of data have overlapping relationships with each other.
- Relational Data Model, process data using the easy-to-understand concept of table.
To use Hierarchical Data Model and Network Data Model you must manage data by keeping physical location and the order of data in mind, so performing flexible and high-speed search of your data is difficult.
That’s why we will be using the Relational Data Model.
What is a Relational Database?
A relational database is a type of database. It uses a structure that allows us to identify and access data in relation to another piece of data in the database. Data in a relational database is organized into tables.
Table, Record, Field, Row & Column
-
A table is a set of data elements (values).
-
A piece of data in a file is called a record.
-
Each item in a record is called a field.
 -
One piece of data or record is called a row.
-
Each item or field is called a column.
Primary Key, Unique & Null

A field is often given an important role in the database, when this happens we call that field the Primary Key. In this example, Product Code is the Primary Key. More information of this in the next section.
A Unique value is a value that cannot be repeated (Like product name, you shouldn’t have two products with the same name).
Null is the absence of value (as seen above in “Remarks”, where there are empty values). Some Fields can be null (depending on the database).
Types of keys
- Key: One or more columns in a database table that is used to sort and/or identify rows in a table. e.g. if you were sorting people by the field salary then the salary field is the key.
- Primary key: A primary key is a one or more fields that uniquely identifies a row in a table. The primary key cannot be null (blank). The primary key is indexed (more on index later).
- Foreign key: A foreign key is a relationship between columns in two database tables (one of which is indexed) designed to insure consistency of data.
- Composite key: A primary key composed of one or more columns. The primary key can be formed using the fields (though not very advisable).
- Natural key: A composite primary key which is composed of attributes (fields) which already exist in the real world (for example First Name, Last Name, Social Security Number).
- Surrogate key: A primary key which is internally generated (typically auto-incremental integer value) that does not exist in the real world (for example, ID which serves to identify the record but nothing else).
- Candidate key: A column, or set of columns, in a table that can uniquely identify any database record without referring to any other data. Each table may have one or more candidate keys, but one candidate key is unique (the primary key).
- Compound key: A composite key consisting of two or more fields that uniquely describe a row in a table. The difference between compound and candidate is that all of the fields in the compound key are foreign keys; in the candidate key one or more of the fields may be foreign keys (but it is not mandatory).
Designing a database
When you try to create a database yourself, the first step is to determine the conditions of the data you are trying to model.
The E-R model
Model used for analysis to make diagrams. In this model you consider the actual world using concepts of entity and relationship.
-
E refers Entity. A recognizable object in the real world. For example, when exporting fruits to other countries, fruit and export destination can be considered entities. Represented with a rectangle.
Each entity has attributes, particular properties that describe the entity (Product Name in Fruit, for example). Represented with an ovallus.
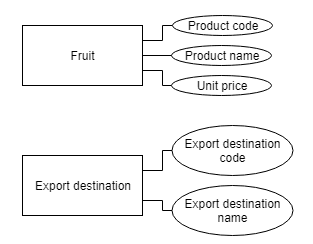
-
R refers relationship. How entities relate with each other. For example, fruits and export destination are associated with each other because you sell fruits to export destinations. Represented with a diamond. Fruit is exported to many Export destinations and Export destination purchases many kinds of fruit. We call this a many-to-many relationship. In the E-R model the number of associations between entities is considered, this is called cardinality.
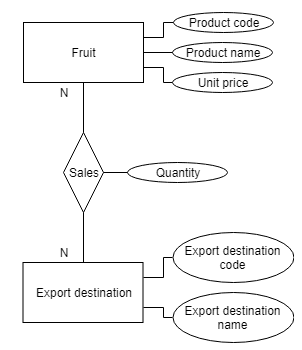 -
Cardinality: Number of associations between entities.
One-to-one relationship (1-1): I only sell fruits to you and you only buy fruits from me.One-to-many (or many-to-one) relationship (n-1 or 1-n): I sell fruits to other families and those families buy fruits only from me.Many-to-many relationship (n-n): You have an example above.### Normalization
Process of tabulating data from the real world for a relational database, following a serie of steps. It is necessary to Normalize data in order to properly manage a relational database. Normalization is used for mainly two purposes:
- Eliminating redundant(useless) data.
- Ensuring data dependencies make sense i.e data is logically stored.
Unnormalized form
The First Normal Form is created from this table. All the attributes you have identified for a given entity are probably grouped together in a flat structure. This is where the process of normalization comes into play, to organize the attributes.
First Normal Form
For a table to be in the First Normal Form, it should follow the following 4 rules:
- It should only have single(atomic) valued attributes/columns: This means, for example, a fruit shouldn’t be in the database with two names.
- Values stored in a column should be of the same domain: This is more of a “Common Sense” rule. In each column the values stored must be of the same kind or type.
- All the columns in a table should have unique names: This rule expects that each column in a table should have a unique name. This is to avoid confusion at the time of retrieving data or performing any other operation on the stored data.
- The order in which data is stored, does not matter: This rule says that the order in which you store the data in your table doesn’t matter.
Important
Before going on you must first know this:
- Prime attributes: Parts of candidate key of a given relational table.
- Non-prime attributes: Not a part of candidate key.
Second Normal Form
- It should be in the First Normal form.
- It should not have Partial Dependency. If a non-prime attribute of the relation is getting derived by only a part of the composite candidate key then such dependency is defined as partial dependency.
Dependency: When you have to use the primary key in order to get an specific value (example, your Name to know your Age).#### Third Normal Form - It is in the Second Normal form.
- It doesn’t have Transitive Dependency. If a non-prime attribute of the relation is getting derived by either another non-prime attribute or the combination of part of the candidate key along with a non-prime attribute then such dependency would be defined as transitive dependency.
Steps for designing a database
Now that you are familiar with the basic terminology and the ER model, you are ready to design a database.
- Determine the purpose of the database.
- Determine the tables needed.
- Identify needed fields.
- Identify exclusive fields.
- Determine relations between tables.
- Define constraints to preserve data integrity (don’t forget normalization).
SQL
When you use the database you have to input or retrieve data using SQL (Structured Query Language). SQL allows you to communicate with the database. Some commands may change depending on the Database Management System (SQL Server for example) you are using.
It’s commands can be broken down into three distinct types:
- Data Definition Language (DDL): Related to the data structure.
CreateDropAlter* Data Manipulation Language (DML): Related to stored data.
SelectInsertUpdateDelete* Data Control Language (DCL): Manages user access.
Select
Most basic SQL statement.
SELECT product_name /*The column you want to see...*/
FROM product; /*...from the table it belongs.*/
Where
Used to specify the information you want.
This statement retrieves all data from the product table that has a unit price greater than or equal to 200.
SELECT * /*This selects every column in the table.*/
FROM product
WHERE unit_price>=200; /*Very easy to understand right?*/
And this one retrieves all data with the product name ‘apple’.
SELECT *
FROM product
WHERE product_name=’apple’;
Comparison operators
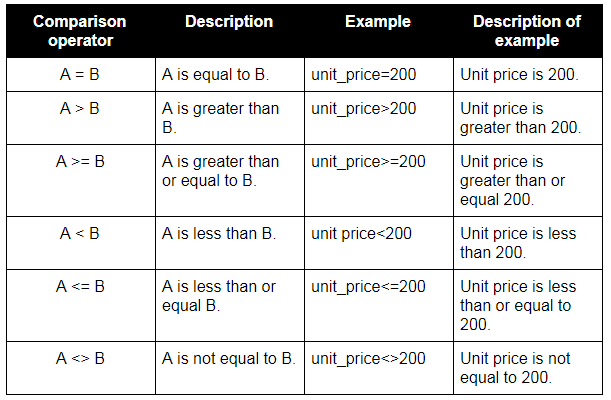
Logical operators
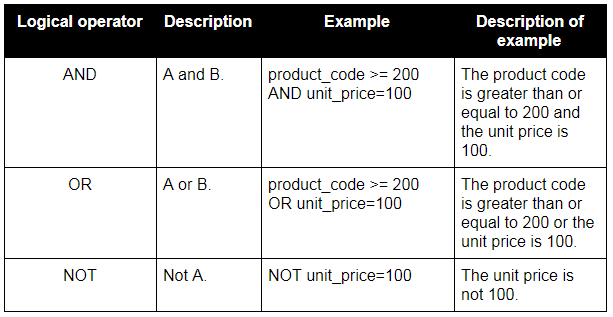
Other
SELECT *
FROM product
WHERE unit_price
BETWEEN 150 AND 200; /*Between doesn’t need explanation I think.*/
SELECT *
FROM product
WHERE unit_price is NULL; /*This one neither.*/
Like
When you don’t know exactly what to search for you can use pattern matching in conditions, by using wildcard characters in a LIKE statement.

Example:
SELECT *
FROM product
WHERE product_name LIKE "%n"; /*Will search for data ending with the letter ‘n’.*/
Order by
Sort data based on a certain column.
SELECT *
FROM product
WHERE product_name LIKE "%n"
ORDER BY unit_price; /*Easy to understand, right*/
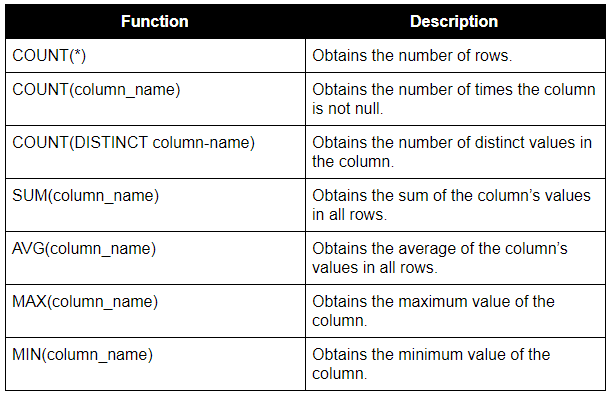
Aggregate functions in SQL
Also known as Set Functions. You can use them to aggregate information such as maximum or minimum values.
Example:
SELECT MAX(unit_price) FROM product
Aggregating data by grouping
If you group data you can obtain aggregated values easily. To group data combine an aggregate function with GROUP BY.
SELECT district, AVG(unit_price)
FROM product
GROUP BY district; /*Output: Average unit price per district*/
HAVING
You can’t use WHERE with aggregate functions, you have to use HAVING.
SELECT district, AVG(unit_price)
FROM product
GROUP BY district;
HAVING AVG(unit_price)>=200; /*Filters result after being grouped.*/
Searching for data
There are more complicated query methods in SQL.
SUBQUERY and IN
You can embed one query in another query (this is called a subquery).
SELECT *
FROM product
WHERE product_code
IN (
SELECT product_code
FROM sales_statement
WHERE quantity>=1000
);
The query in parentheses is performed first. The other SELECT is performed with the result. The IN operator allows multiple WHERE values (that’s why the first select works with the second).
Correlated query
A subquery may refer to data from the outer query, this is called a correlated query.
SELECT *
FROM sales_statement U /*Alias? Maybe more on this later*/
WHERE quantity>
(
SELECT AVG(quantity)
FROM sales_statement
WHERE product_code=U.product_code
);
Alias
SQL aliases are used to give a table, or a column in a table, a temporary name. Often used to shorten column names to make working with them easier (mostly in joins). An alias only exists for the duration of the query.
SELECT o.OrderID, o.OrderDate, c.CustomerName
FROM Customers AS c, Orders AS o
WHERE c.CustomerName="Around the Horn" AND c.CustomerID=o.CustomerID;
Joining tables
JOIN is used to combine rows from two or more tables, based on a related column between them.
Different Types of SQL JOINs
Here are the different types of the JOINs in SQL:
-
(INNER) JOIN: Returns records that have matching values in both tables.
 -
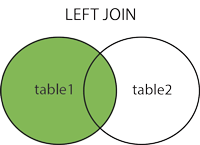
LEFT (OUTER) JOIN: Return all records from the left table, and the matched records from the right table.
 -
RIGHT (OUTER) JOIN: Return all records from the right table, and the matched records from the left table.
 -
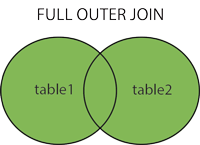
FULL (OUTER) JOIN: Return all records when there is a match in either left or right table.
Equi join
Join against equality or matching column(s) values of the associated tables. An equal sign (=) is used as comparison operator in the where clause to refer equality.
SELECT *
FROM table1
JOIN table2
[ON (join_condition)]
/*You can also do it without JOIN*/
SELECT column_list
FROM table1, table2....
WHERE table1.column_name =
table2.column_name;
Creating a table
The code can be different depending on which kind of database you are working with.
CREATE TABLE product /*This line needs no explanation, right?*/
(
product_code INT NOT NULL,
product_name VARCHAR(255),
unit_price INT,
PRIMARY KEY(product_code)
);
- INT means integers.
- VARCHAR means database expects text. 255 means no more than 255 characters.
Constraints on a table
Specifications for a table to prevent data conflicts.

Inserting data into a table
INSERT INTO product (product_code, product_name, unit_price)
VALUES (101, "melon", 800);
INSERT INTO product VALUES (101, "melon", 800);
Both statements do the same. You insert data in the type and order it was defined. Remember the constraints (like primary keys).
Updating rows
Allows you to modify data inside a table.
UPDATE product
SET product_name="cantaloupe" /*New value*/
WHERE product_name="melon"; /*Specific value to overwrite*/
Deleting rows
Delete data from a table.
DELETE FROM product
WHERE product_name="apple"; /*Row to delete*/
Creating a view
You can create a virtual table that exists only when it is viewed by a user. This is a view. The table from which a view is derived is called a base table.
CREATE VIEW expensive_product /*The view name is "expensive_product"*/
(product_code, product_name, unit_price)
AS SELECT *
FROM product
WHERE unit_price>=200;
To use the view:
SELECT *
FROM expensive_product
WHERE unit_price>=500;
It is convenient to create a view when you want to make part of the data in a table public.
DROP
Allows you to delete:
/*A view:*/
DROP VIEW expensive_product;
/*A base table:*/
DROP TABLE product;
/*A database:*/
DROP DATABASE name;
Operating a database
Transactions
A unit of data operations is called a transaction. Example: Reading data, writing data. A transaction always ends with a commit or a rollbackoperation.
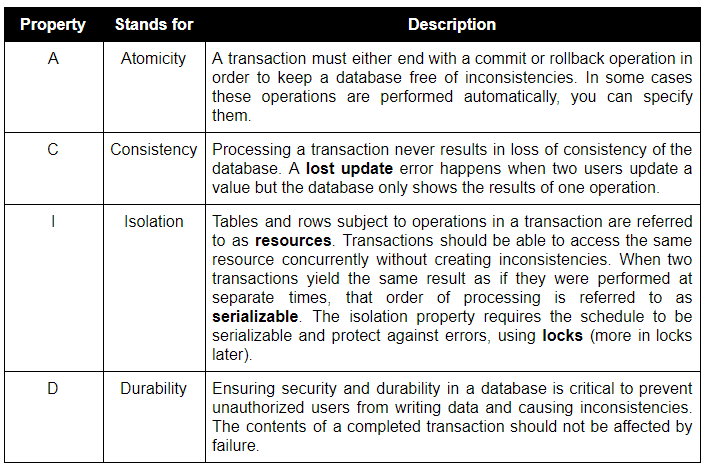
It is important to ensure that multiple transactions can be processed without conflicting data. It is also important to protect data from inconsistencies in case a failure occurs while a transaction is being processed. To that end, the following table lists the properties required for a transaction, which memorably spell ACID.
Properties required for a transaction
Commit
Operations in the database are finalized when each transaction is processed correctly. That finalization is called a commit operation.
Lock
Operations by many users are controlled so that nothing goes wrong when they access the database concurrently. For that purpose, a method called Lock is used.
You lock data to prevent it from being erroneously processed.
If I perform some operations on the database, the data is locked until my operations are finished, then is unlocked to be used by another user and the data is locked again, and unlocked when this user finishes.
Although a lock has its own role in a database, it should not be overused because it can hinder its purpose: sharing data with a lot of people. So we use different types of locks depending on the situation.
Shared lock
For example, you can use a shared lock for a read operation when it is the only operation needed. Other users can read data but cannot perform a write operation on it.
Exclusive lock
When performing a write operation a user applies an exclusive lock. When it is applied other users cannot read or write data.
Concurrency control
When a lock is used to control two or more transactions. Concurrency allows as many users as possible to use a database at one time while preventing data conflicts from ocurring.
Two phase locking
In order to make sure a schedule is serializable we need to obey specific rules for setting and releasing locks. One of these rules is two-phase locking, for each transaction two phases should be used: one for setting locks and the other for releasing them.
Locking granularity
There are a number of resources that can be locked. The extent to which resources are locked is referred to as granularity. Coarse granularity occurs when many resources are locked at once, and fine granularity occurs when few resources are locked. When granularity is coarse (or high) the number of locks needed per transaction is reduced, reducing the amount of processing required.
Other concurrency controls
Simpler methods can be used when you have a small number of transactions or a high number of read operations.
- Timestamp Control: A label containing the time of access (timestamp) is assigned to data accessed during a transaction. If another transaction with a later timestamp has already updated the data, the operation will be not permitted. When a read or write operation is not permitted, the transaction is rolled back.
- Optimistic Control: This method allows a read operation. When a write operation is attempted, the data is checked to see if any other transactions have occurred. If another transaction has already updated the data, the transaction is rolled back.
Levels of isolation
You can set the level of transactions that can be processed concurrently, this is referred to as the isolation level. The SET TRANSACTION statement can be used to specify the isolation level of the following transactions:
- READ UNCOMMITTED
- READ COMMITTED
- REPETEABLE READ
- SERIALIZABLE
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
Depending on the isolation level setting, any of the following actions may occur:
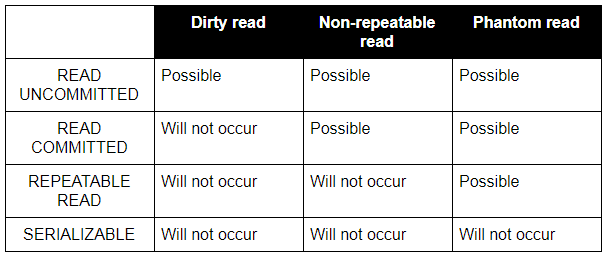
- Dirty read: When transaction2 reads a row before transaction1.
- Non-repeatable read: When a transaction reads the same data twice and gets a different value.
- Phantom read: When a transaction searches for rows matching a certain condition but finds the wrong rows due to another transaction’s changes.
Deadlock
Two users use an exclusive lock on two tables. Then, both will try to apply the same lock to the other table. Since each of them must wait for the lock applied by the other user to be released, neither can proceed with any operation. This situation is called a deadlock and cannot be solved unless one of the locks is released.
Rollback
When a deadlock occurs, you can look for transactions that have been queued for a certain time and cancel them. Cancelling a transaction (every operation in it) is called a rollback. For example, if you wanted to apply a discount to all fruits with a price of 150 or more and one of them fails, you cancel everything and the database behaves as if no operation had been performed.
Database security
If you don’t secure the database, data can be deleted or modified without permission. A good solution may be to require usernames and passwords to limit users and limit operations to certain users (for example, only an administrator can DROP a table).
GRANT
You can grant access to users using GRANT.
GRANT SELECT, UPDATE ON product TO Overseas_business_department;
Database privileges

Granting privilege with WITH GRANT OPTION enables the user to grant privileges to other users.
GRANT SELECT, UPDATE ON product TO overseas_business_department WITH GRANT OPTION;
REVOKE
To take away a user’s privileges uso REVOKE.
REVOKE SELECT, UPDATE ON product FROM overseas_business_department;
Some database products can group a number of privileges and grant them to multiple users at once. Grouping makes privilege management easier. Using views enables even more security, enabling the view to certain users you also protect the selected data in the view.
Disaster recovery
A database needs to have a mechanism that can protect data in the system in the event of a failure. To ensure durability of transactions is mandatory that no failure can create incorrect or faulty data. To protect itself from failure a database performs various operations which include creating backup and transaction logs.
Records called logs are kept whenever a data operation is performed. When a problem has occurred in the system you first restart the system and utilize logs to recover the database. The recovery method varies depending on whether or not the transaction has been committed.
Types of failures
- Transaction failure: When a transaction cannot be completed due to an error in itself. The transaction is rolled back when this failure occurs.
- System failure: When system goes down because of a power failure or other disruption. If the problem occurred after a transaction had already been committed, you can recover data by reapplying the operations to the database. This method is called rolling forward. If the transaction hasn’t been committed, a rollback takes place. The value before the update is referenced to cancel the transaction.
- Media failure: When the hard disks containing the database is damaged.
Checkpoints
In order to improve the efficiency of a write operation in a database, a buffer (segment of memory used to temporarily hold data) is often used to write data in the short term. The contents of the buffer and the database are synchronized, and then a checkpoint is written. When the database writes a checkpoint, it doesn’t have to perform any failure recovery for transactions that were committed before the checkpoint. Transactions that weren’t committed before the checkpoint must be recovered.
Indexing
As the database grows and more people begin using it some problems may appear. The greater the volume of data, the slower a search operation becomes.
An index works as in a book. A blind search of a piece of information in a book would take time, so you check the index to speed up your search. It is very time consuming to browse all rows when searching for certain data. If you create indexed for product codes you can instantly learn where product data is stored for a product assigned. It tells you where on the disk is located, reducing the disk access count and therefore accelerating future searches.
It is up to the database administrator to add indexes. Creating too many indexes may lead to inefficiency (imagine a large number of indexes in a book, it won’t do any good).
Stored programs
Types

Program logic inside the database server (basically queries inside the server). They help reduce the load on the network because it eliminates the need for frequent transfers of SQL queries.
Distributed database
A database in which not all storage devices are attached to a common processor but in multiple computers, located in the same physical location or dispersed over a network of interconnected computers. Keep in mind that it may be handled as a single database.
Practice
Practice
- W3Schools has a lot of basic SQL exercises, practice them.
- W3Resources has a wide varierty of exercises for you to improve your skills.
- The Manga Guide to Databases includes exercises with its answers, not only SQL but also for the design phase.
- Try also Google or Youtube.
by: Lucas Olivera
#sql #big-data