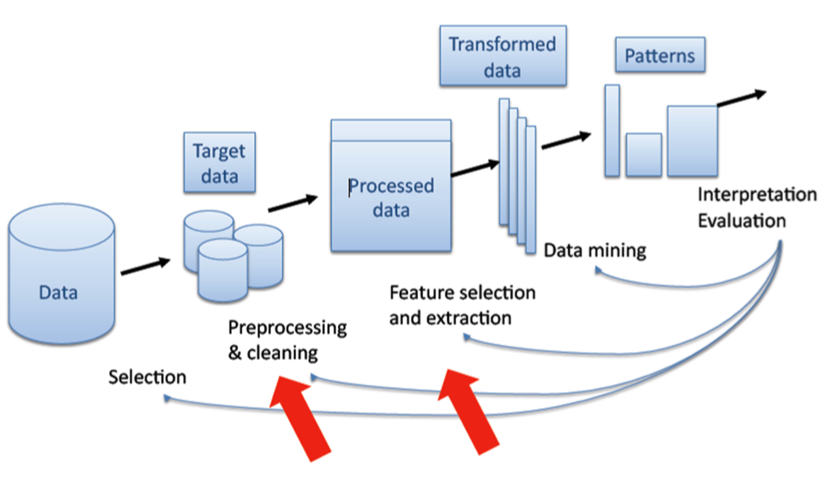
During the Data mining process, we are given raw data. Before visualizing or interpreting data, we have to make sure that certain refinement methods are applied to the data before it is available for analysis. This refinement process includes Preprocessing or cleaning the data, such as removing the null or blank values from the data. Next is the Feature selection or Feature Extraction Technique, which is utilized in PCA where the least contributing features are neglected or removed as per requirement. The last stage is the Data Transformation, where the user will apply normalization techniques to scale all the features in the same range.
What is PCA?
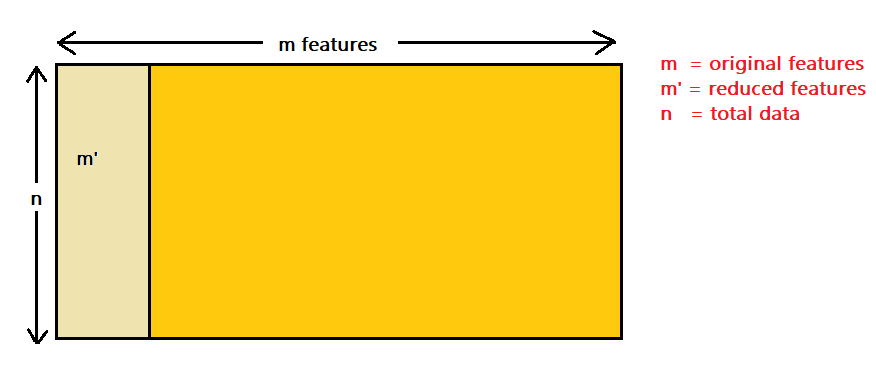
Image by Author
In the current world, when we perform data analysis tasks, we analyze complex data, i.e., multidimensional data. After analyzing the data, we plot it and observe some patterns or utilize it to train other machine learning models. Dimensions can be thought of as a view using which we can observe a point in space from any axes. As the point’s dimensions increase, it becomes difficult to visualize it, and perform computations on it becomes complex. So it becomes necessary to keep a check on dimensions, and we need to find ways to reduce the dimensions. To solve this issue, we introduced PCA.
Principal Component Analysis is the Unsupervised Learning Algorithm. PCA implements the Dimensionality Reduction technique. The goal of PCA is the removal of irrelevant features while developing a model. PCA extracts the most dependent features contributing to the output.
Why we need it?
- Removal of irrelevant features.
- Improve the prediction accuracy of models.
- Improve the reduction of storage and computation cost.
- Improve the understanding of data and the model.
#data-mining #machine-learning #data-preprocessing #data-science #dimensionality-reduction