Fetching tables from PDF files is no more a difficult task, you can do this using a single line in python.
What you will learn
- Installing a tabula-py library.
- Importing library.
- Reading a PDF file.
- Reading a table on a particular page of a PDF file.
- Reading multiple tables on the same page of a PDF file.
- Converting PDF files directly to a CSV file.
Tabula
Tabula is one of the useful packages which not only allows you to scrape tables from PDF files but also convert a PDF file directly into a CSV file.
So let’s get started…
1. Install tabula-py library
pip install tabula-py
2. Importing tabula library
import tabula
3. Reading a PDF file
lets scrap this PDF data into pandas Data Frame.
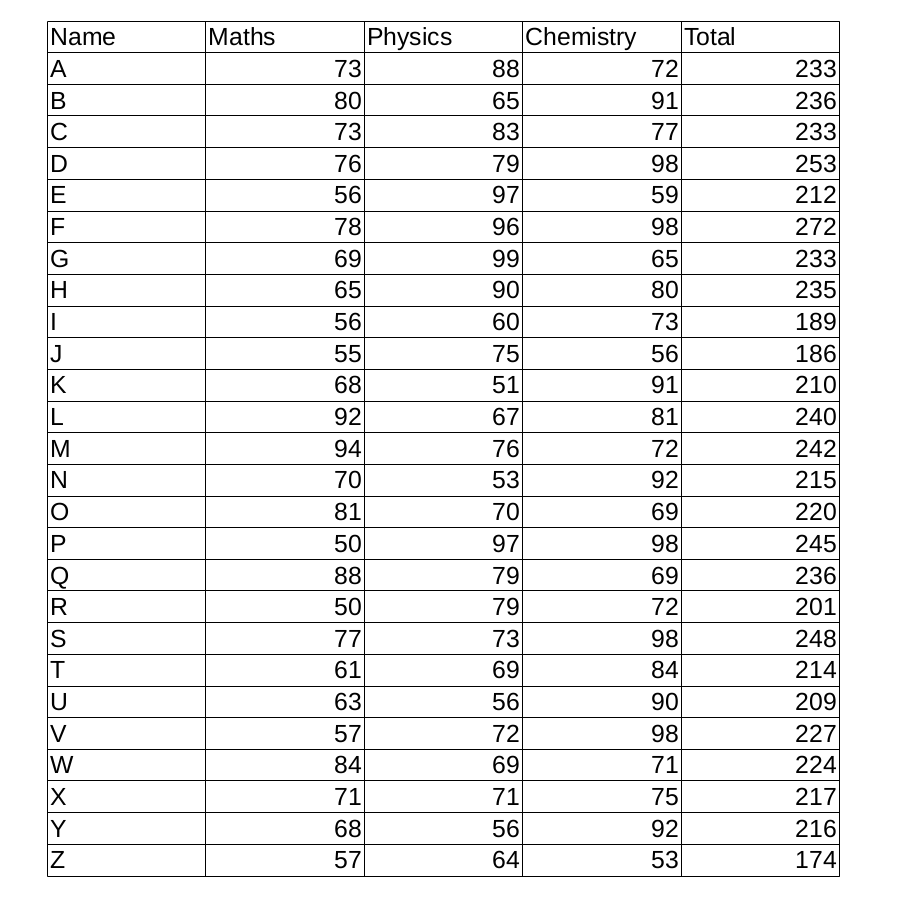
image by Satya Ganesh
file = "data1.pdf"
table = tabula.read_pdf(file,pages=1)
table[0]
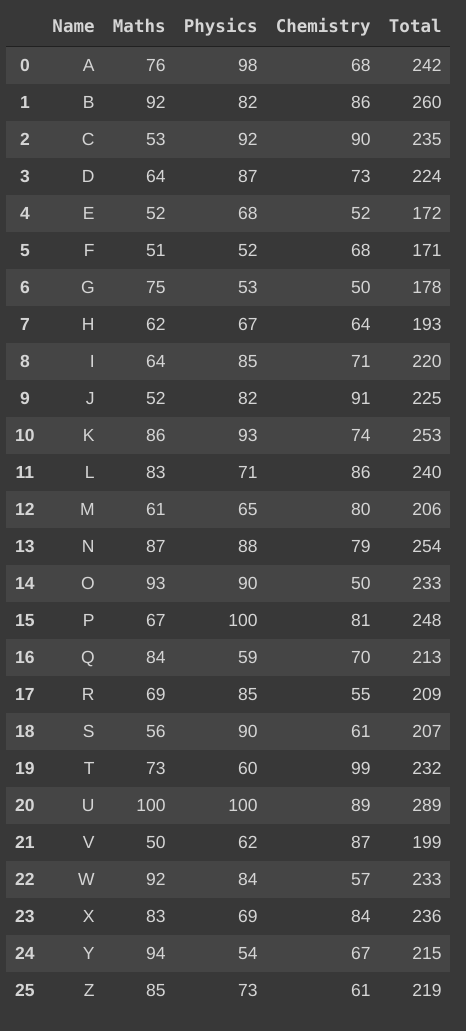
Take a look at the output of above code snippet executed in Google Colabs
#machine-learning #programming #data-science #data-scraping #data #data analysis
5.65 GEEK