BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based architecture released in the paper “Attention Is All You Need**_” in the year 2016 by Google. The BERT model got published in the year 2019 in the paper — “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. _**When it was released, it showed the state of the art results on GLUE benchmark.
Introduction
First, I will tell a little bit about the Bert architecture, and then will move on to the code on how to use is for the text classification task.
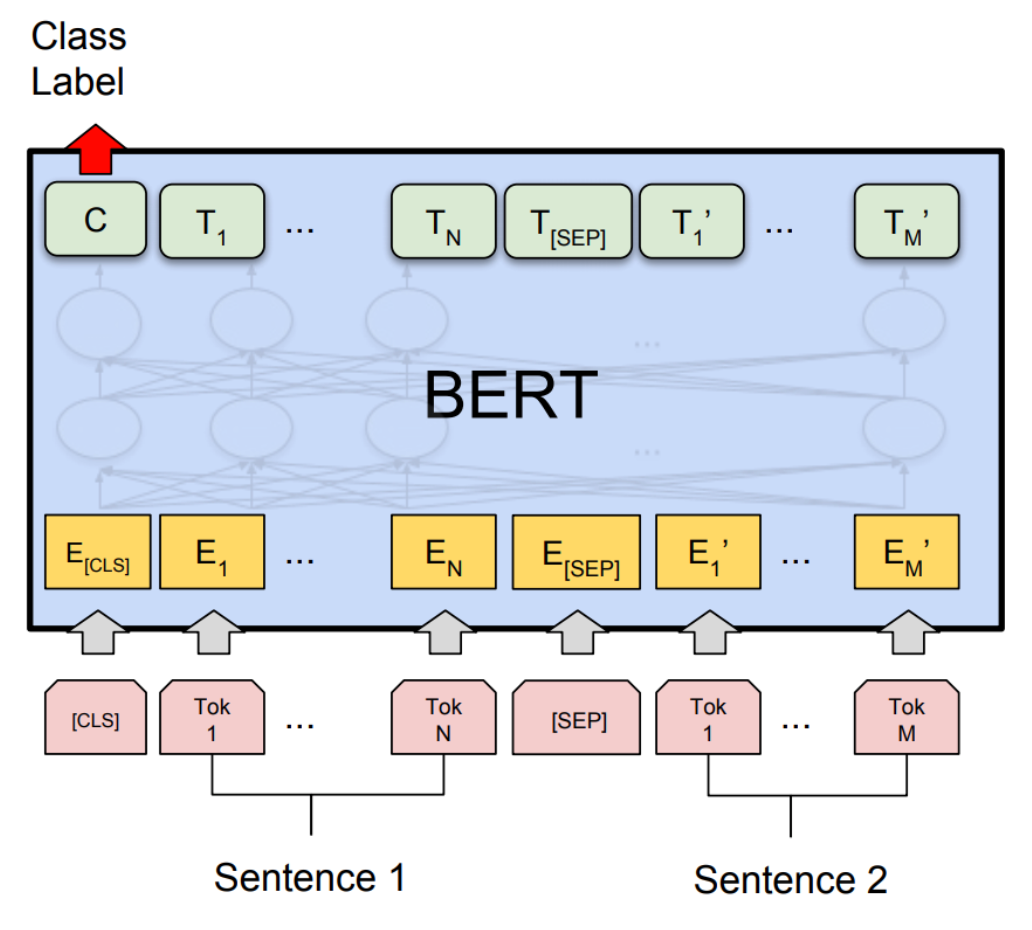
The BERT architecture is a multi-layer bidirectional transformer’s encoder described in the paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
There are two different architecture’s proposed in the paper. **BERT_base **and **BERT_large. **The BERT base architecture has L=12, H=768, A=12 and a total of around 110M parameters. Here L refers to the number of transformer blocks, H refers to the hidden size, A refers to the number of self-attention head. For BERT large, L=24, H=1024, A=16.
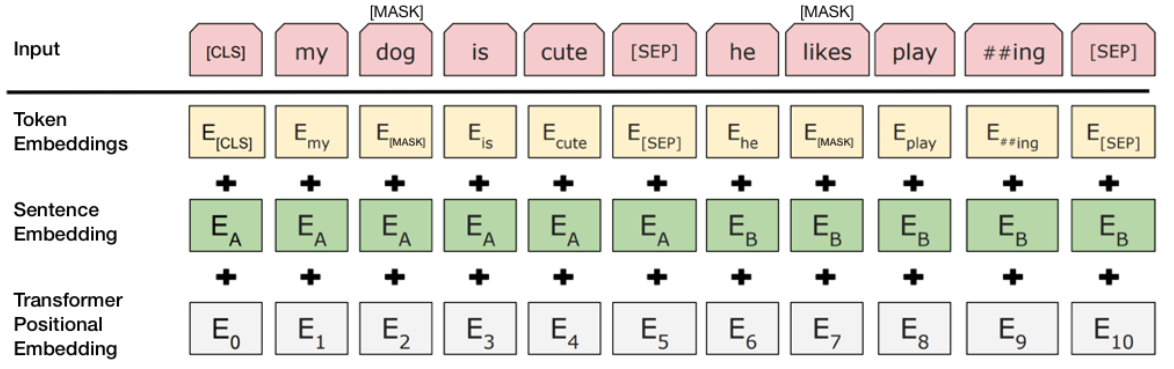
Source:- https://www.kdnuggets.com/2018/12/bert-sota-nlp-model-explained.html
The input format of the BERT is given in the above image. I won’t get into much detail into this. You can refer the above link for a more detailed explanation.
Source Code
The code which I will be following can be cloned from the following HuggingFace’s GitHub repo -
Scripts to be used
Majorly we will be modifying and using two scripts for our text classification task. One is **_glue.py, _**and the other will be **_run_glue.py. _**The file glue.py path is “_transformers/data/processors/” _and the file run_glue.py can be found in the location “examples/text-classification/”.
#deep-learning #machine-learning #text-classification #bert #nlp #deep learning