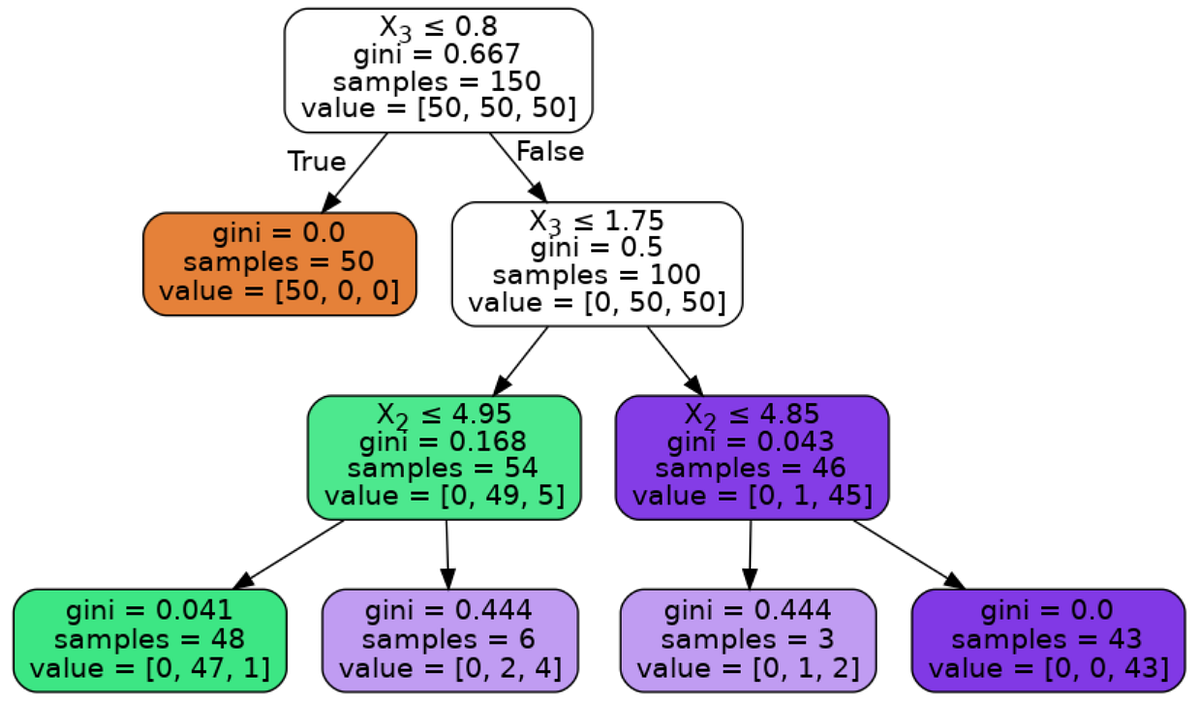
Both of Regression Trees and Classification Trees are a part of CART (Classification And Regression Tree) Algorithm. As we mentioned in Regression Trees article, tree is composed of 3-major parts; root-node, decision-node and terminal/leaf-node.
The criteria used here in node splitting differs from that being used in Regression Trees. As before we will run our example and then learn how the model is being trained.
There are three commonly measures are used in the attribute selection Gini impurity measure, is the one used by CART classifier. For more information on these, see Wikipedia.
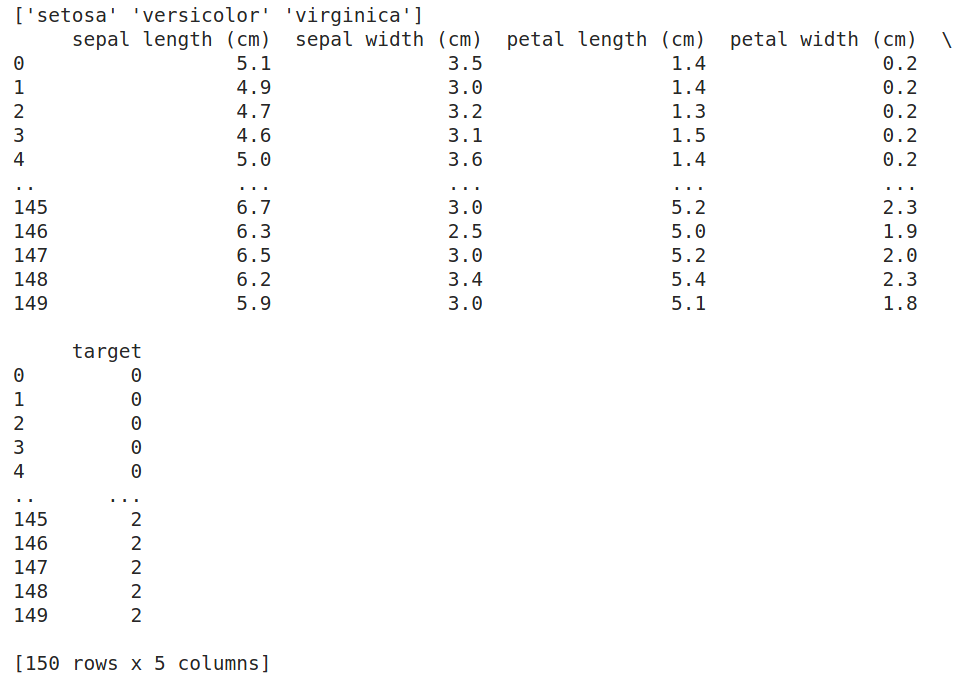
Data set being used is iris data set
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from six import StringIO
from IPython.display import Image
# pip/conda install pydotplus
import pydotplus
from sklearn import datasets
iris = datasets.load_iris()
xList = iris.data # Data will be loaded as an array
labels = iris.target
dataset = pd.DataFrame(data=xList,
columns=iris.feature_names)
dataset['target'] = labels
targetNames = iris.target_names
print(targetNames)
print(dataset)

Iris Flowers
How a Binary Decision Tree Generates Predictions
When an observation or row is passed to a non-terminal node, the row answers the node’s question. If it answers yes, the row of attributes is passed to the leaf node below and to the left of the current node. If the row answers no, the row of attributes is passed to the leaf node below and to the right of the current node. The process continues recursively until the row arrives at a terminal (that is, leaf) node where a prediction value is assigned to the row. The value assigned by the leaf node is the mean of the outcomes of the all the training observations that wound up in the leaf node.
How to split the nodes
Classification trees split a node into two sub-nodes. Splitting into sub-nodes will increase the homogeneity of resultant sub-nodes. In other words, we can say that the purity of the node increases with respect to the target variable. The decision tree splits the nodes on all available variables and then selects the split which results in most homogeneous/pure sub-nodes.
There are major measures being used to determine which attribute/feature is used for splitting and which value within this attribute we will start with. Some of these measures are:
- Gini index (Default in SciKit Learn Classifier).
- Entropy.
- Information gain.
We will start with Gini index measure and try to understand it
Gini Index
Gini index is an impurity measure used to evaluate splits in the dataset. It is calculated by getting the sum of the squared probabilities of each class (target-class) within a certain attribute/feature then benig subtacted from one.
#machine-learning #mls #decision-tree #decision-tree-classifier #classification #deep learning