**Objective: **Generate new sentences automatically in continuation of given input sentences.
Road-Map:
- Business problem
- Data discussion
- EDA
- Data pipeline
- Model Architecture
- Inference
- Comparision
- Conclusion
- Future work
- References
Introduction
As time flies from the seventeenth century when philosophers such as Leibniz and Descartes put forward proposals for codes which would relate words between languages to 1950 when Alan Turing published an article titled “Computing Machinery and Intelligence” — NLP(Natural language processing) was set to be explored. NLP has seen the evolution from complex sets of hand-written rules (1980) to statistical models, machine learning models to deep learning models. Today, tasks from NLP like Text classification, Text summarization, Question-Answering systems, Language modelling, Speech recognition, Machine translation, Caption Generation, Text generation are leveraging the state of the art models like Transformer, BERT, Attention. Although nuts and bolts are — ‘Neurons’, their connectivity, training, learning and behaviour depend on model to model like in RNNs, seq2seq, Encoder-Decoder, Attention, Transformers, etc. Let’s explore one of the tasks — Text Generation.
1. Business Problem
What if instead of note down the sentences manually suppose our well designed and learnt system either generate or suggest the next paragraph or sentences? It will make writing easier. It will suggest the continuation of a sentence. It will generate new headlines or stories or articles or chapters of a book. Gmail is also taking advantages of this concept in Auto-reply and Smart-compose(paper).
- Problem Description
Develop a model, which can learn to generate the next sentences or words in continuation and can complete the paragraph or content.
- Role of Deep learning
As we all are aware of the abilities of DL to learn from data as ANNs were inspired by information processing and distributed communication nodes in biological systems.
So, we can pose this problem as DL task, in which we will feed our model with data and train it in such a way that it can predict next sequences. We will use all tools and techniques of DL to make our model learn itself.
2. Data Discussion
I have used data on space and astronomy news from here. I have scrapped almost 3700 articles from the website. You can also find the script for scrapping here.
As all articles are scraped from the web, so they contain some extra information regarding adds, pop-ups, video links, information about sharing on various social platforms, etc. Therefore it’s better to clean data properly, as our model will learn from the gathered data.
3. EDA
Here it comes the turn to explore and understand data. It is often said in the field of Data Science that ‘The more you understand the Data, the more your model can learn from it”! So let’s try to explore it.
3.1 Cleaning
Our primary goal is to make our text data clean and crisp so that our model can learn and understand the patterns and behaviour of the sentences in English.
- As I mentioned earlier, our scraped articles had some extra unnecessary information which we have to remove.
- We will convert our text into lowercase so that our vocab size get decreased.
- We will replace all numbers with ‘numtag’ and alphanumeric words with ‘alphanumeric’ tags to reduce our vocab size.
- We will remove all punctuations except (.,?!) to generate meaningfully sentences.
data cleaning
def cleaning_files(file):
'''Function to clean and replace some words with tags.'''
data = []
with open(DIR_PATH + file) as fp:
ID = file.split('.')[0]
for line in fp:line = line.strip()
replaced = " ".join(line.split())
# replace some tags with ''
replaced = re.sub('(\(adsbygoogle.*).push\({}\);','',replaced)
replaced = re.sub('Further Reading:.*', '', replaced)
replaced = re.sub('Share this:Click.*', '', replaced)
replaced = re.sub('Podcast \(.*\)', '', replaced)
replaced = re.sub('Subscribe:.*', '', replaced)
replaced = re.sub('Video caption:.*', '', replaced)
replaced = re.sub('Image Credit:.*', '', replaced)
replaced = re.sub('Credit:.*', '', replaced)
replaced = re.sub('((http|https)\:\/\/)?[a-zA-Z0-9\.\/\?\:@\-_=#]+\.([a-zA-Z]){2,6}([a-zA-Z0-9\.\&\/\?\:@\-_=#])*','', replaced)
replaced = re.sub('[0-9]+[,\.][0-9]+','numtag', replaced)
replaced = re.sub('([a-z]+)?[0-9]+([a-z]+)?','alphanumeric', replaced)
replaced = re.sub(r' +',' ', replaced)
replaced = re.sub("([?.!,'])", r" \1 ", replaced)
replaced = re.sub(r"[^a-zA-Z0-9?.!,]+", " ", replaced)
data.append(replaced.lower())
title = data.pop(0)
content = ' '.join(data)
return ID, title, content
view raw
cleaning.py hosted with ❤ by GitHub
3.2 Data analyzing
We will analyze words as well as characters from our text data. Let’s analyze various plots for total words and total characters from our articles.
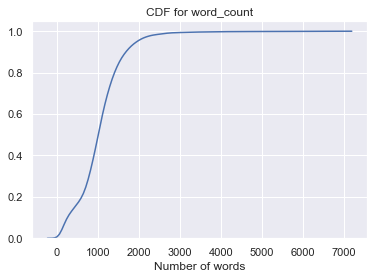
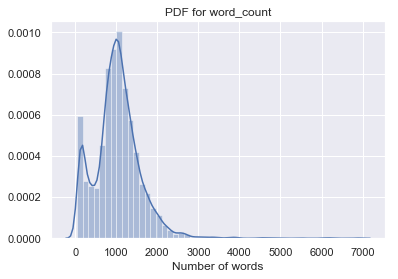
PDF and CDF of words
#text-generation #lstm #gpt-2 #attention #deep-learning #deep learning