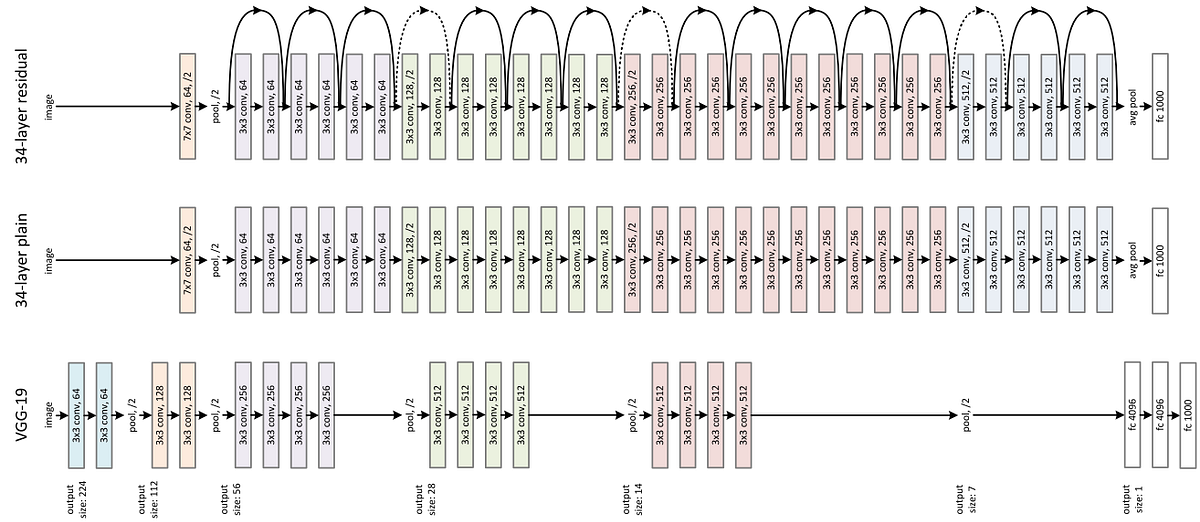
In this blog post, I’m going to present to you the **ResNet **architecture and summarize its paper, “Deep Residual Learning for Image Recognition” (PDF). I’ll explain where it comes from and the ideas behind this architecture, so let’s get into it!
Introduction
At the time the ResNet paper got released (2015), people started trying to build deeper and deeper neural networks. This is because it improved the accuracy on the ImageNet competition, which is a visual object recognition competition made on a dataset with more than 14 million images.
But at a certain point, accuracies stopped getting better as the neural network got larger. That’s when ResNet came out. People knew that increasing the depth of a neural network could make it learn and generalize better, but it was also harder to train it. The problem wasn’t overfitting because the test error wasn’t going up when the training error was low. That’s why residual blocks were invented. Let’s see the idea behind it!
The Idea Behind the ResNet Architecture
The idea behind the ResNet architecture is that we should at least be able to train a deeper neural network by copying the layers of a shallow neural network (e.g. a neural network with five layers) and adding layers into it that learn the identity function (i.e. layers that don’t change the output called identity mapping). The issue is that making the layer learn the identity function is difficult because most weights are initialized around zero, or they tend toward zero with techniques such as weight decay or l2 regularization.
#neural-networks #programming #deep-learning #machine-learning #artificial-intelligence