Many associations in the world like the biological ecosystems, government and corporations are physically decentralized however they are unified in the sense of their functionality. For instance, a financial institution operates with a global policy of maximizing their profits, hence appearing as a single entity; however, this entity abstraction is an illusion, as a financial institution is composed of a group of individual human agents solving their optimization problems with our without collaboration. In deep reinforcement learning, the process which maximizes the objective function parameterizes the policy as a function from states to actions. The policy function parameters are fine-tuned depending on the gradients of the defined objective function. This approach is called the monolithic decision-making framework as the policy function’s learning parameters are coupled globally solely using an objective function.
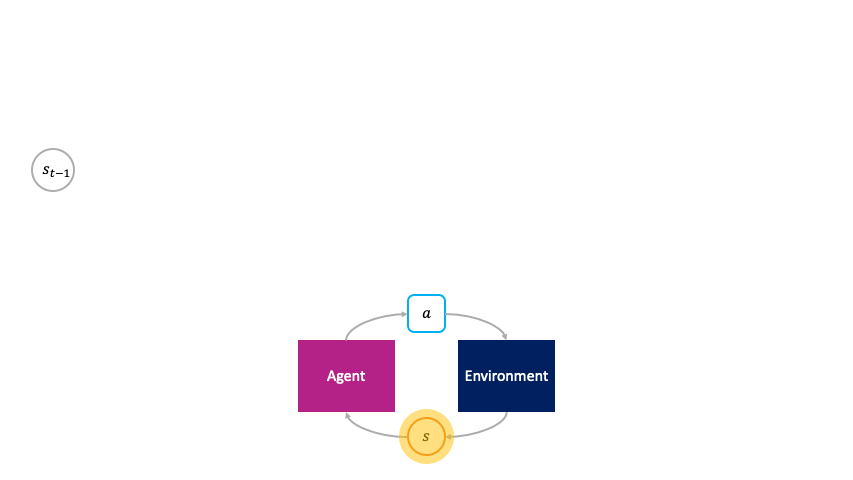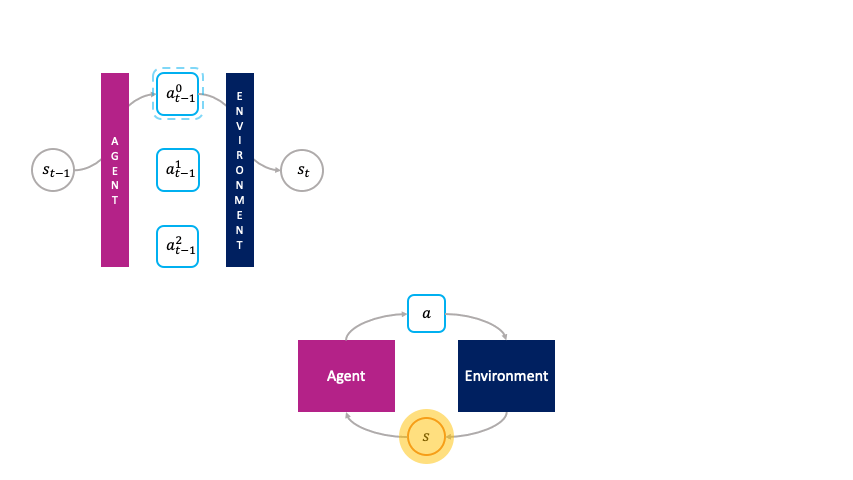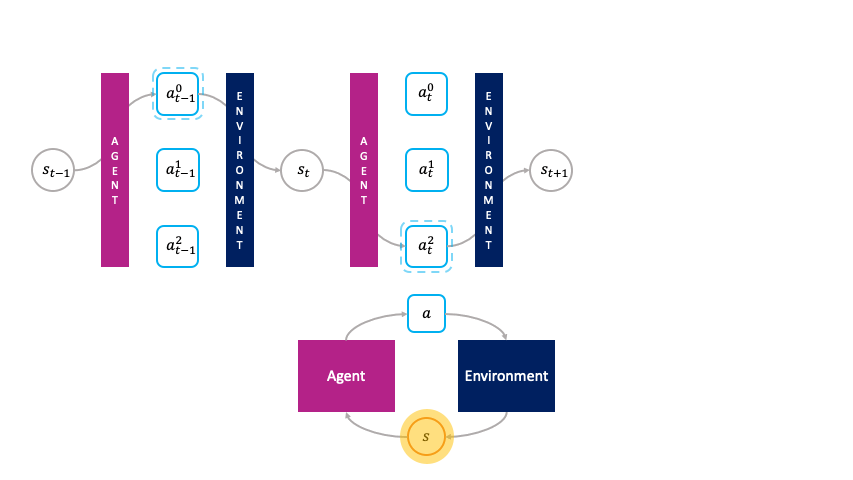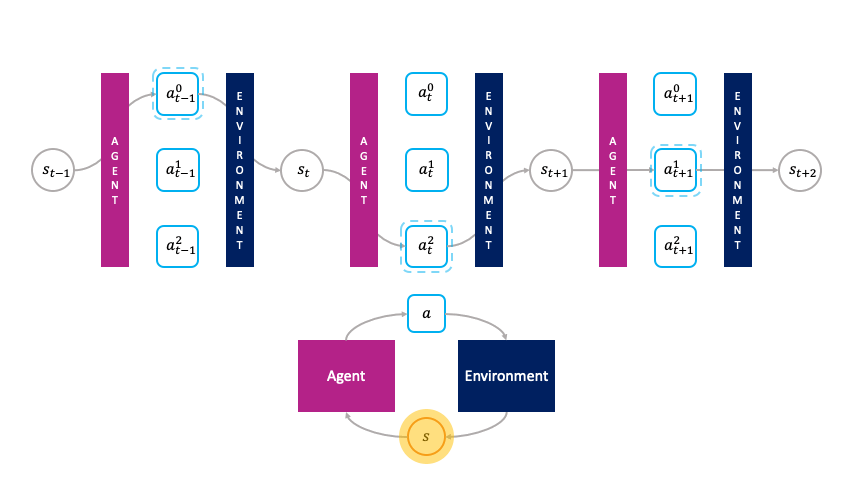
Note how actions are chosen passively by the agent in the monolithic decision-making framework.
Having covered a brief background of a centralized reinforcement learning framework, let us move forward to some promising decentralized reinforcement learning frameworks.
Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions
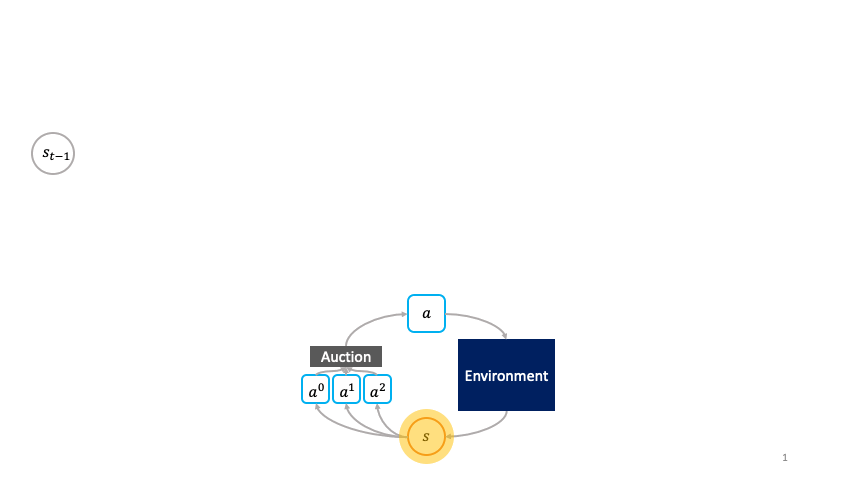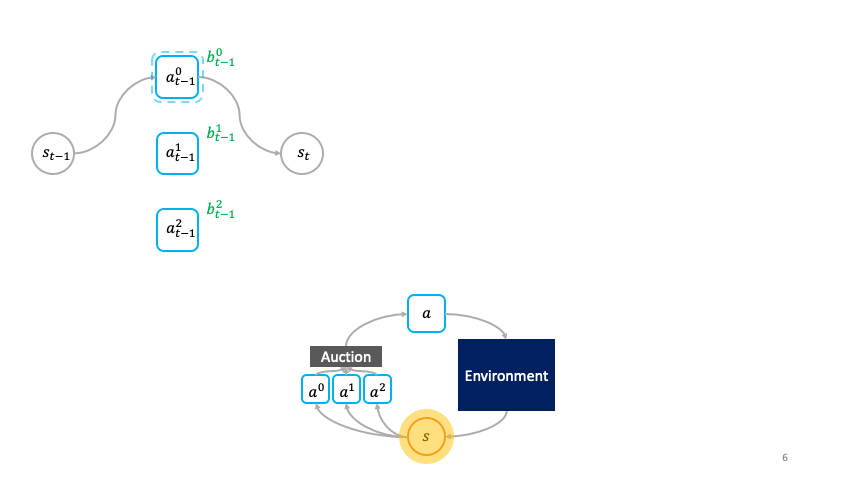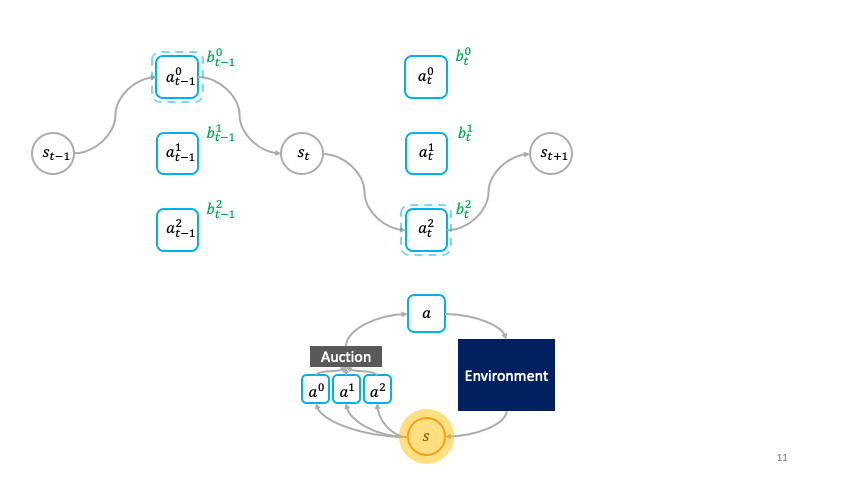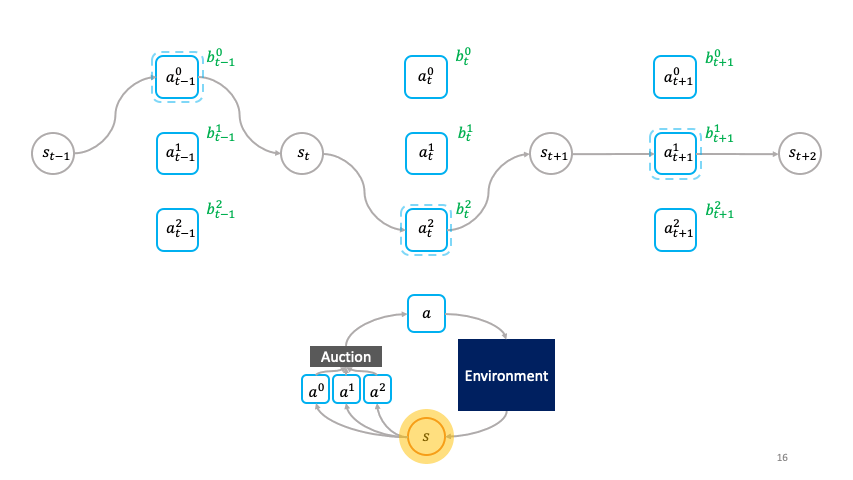
A class of decentralized RL algorithms which establishes the relationship between the society (global policy or super-agent) and the agent (actions) at different levels of abstraction is proposed in [1]. A societal decision-making framework is defined at the _highest _level of abstraction to understand the relationship between the optimization problem solved locally by the agent and the optimization problem solved globally by society. At each state, the agent at the local level bids in an auction and the auction’s winner transmutes the state from one to another; after which it sells the transformed state to other agents, hence propagating a chain of local economic transactions. A question now arises regarding the characteristics of the auction mechanism and the society which enables the implicit emergence of the global solution simply from the agents optimizing their auction utilities. A solution to the above question is provided at the _second stage of abstraction through the cloned Vickrey society **which ensures that the agents’ dominant strategy equilibrium matches the optimal policy of the society. The truthfulness property of Vickrey auction as detailed in [2] guarantees the aforementioned outcome. At the _third _level of abstraction, a class of decentralized reinforcement learning algorithms is proposed which leverages the agents’ auction utilities as optimization objectives and hence learns the societal policy which is global in space and time using only the credit assignment for agents’ learnable parameters which is held locally in space and time. The _fourth _level of abstraction involves the implementation of the clones Vickrey society utilizing the proposed decentralized reinforcement learning algorithms and coming up with an optimal set of design choices titled the credit conserving Vickrey implementation _**that performs the best at both the global and local levels.
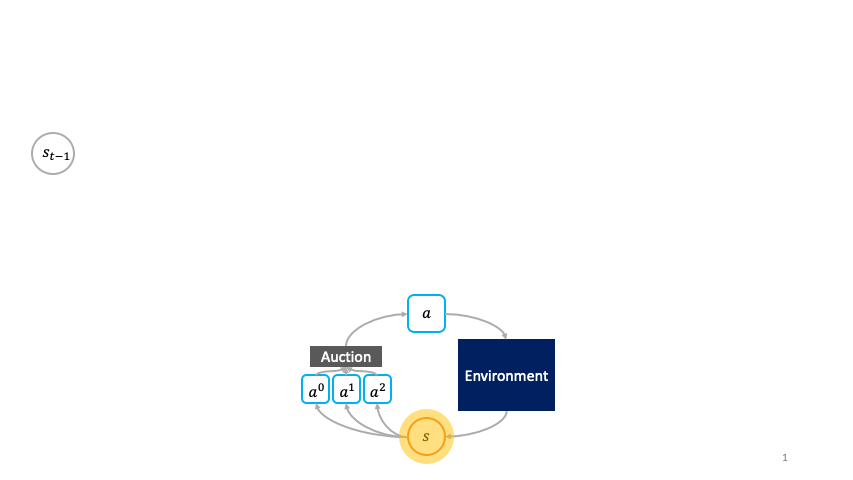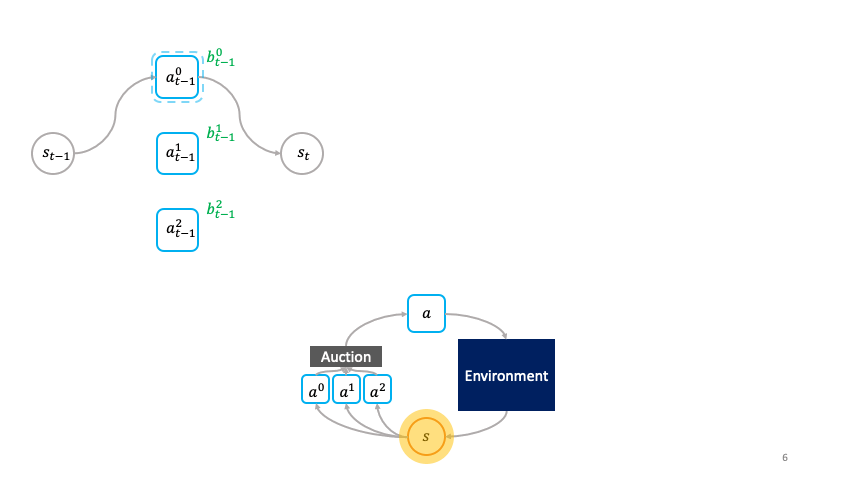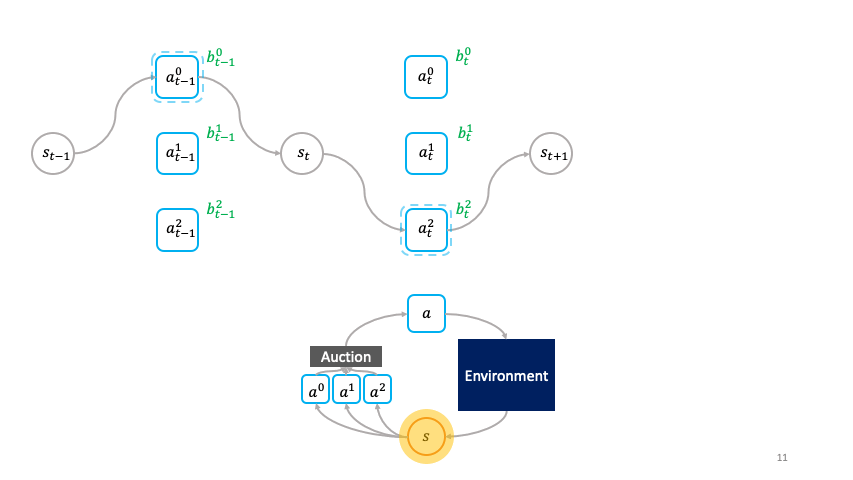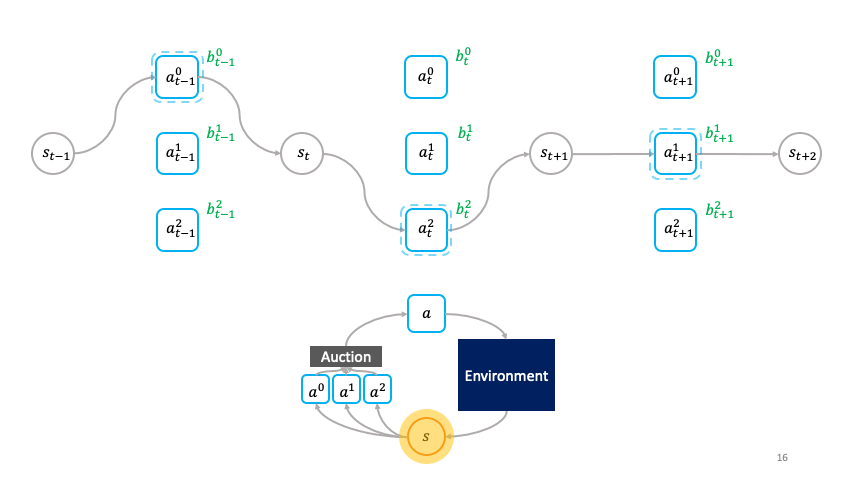
Note how actions choose themselves actively as to when to activate in the societal decision-making framework.
Societal Decision-making
Let us set up the societal based decision-making framework by relating the Markov Decision Processes (MDP) and auction mechanisms under a unifying notation.
In the MDP (global) environment, the input space is the state space S and the output space is the action space A. An agent represents a policy π: S → A. The transition function Τ: S × A → S, the reward function r: **_S × A → ℝ _**and the discount factor γ are used to specify an objective function as follows:
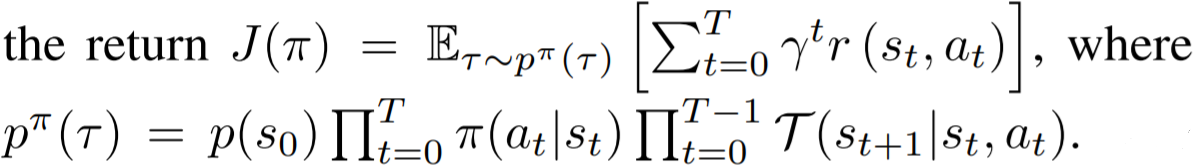
At a given state s, the agent performs the task of maximizing J(π) and hence finding the optimal action defined as follows:
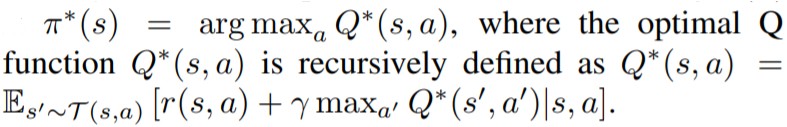
In the auction (local) environment, the input space is the single auction item s and the output space is the bidding space 𝔅. Each of Nagents bid for an auction item in a competition using its respective bidding policy ψᵢ: {s} → 𝔅. Let b be the vector representing the bids made by N agents, then the utility for each agent can be defined using vₛ: the vector signifying each agent’s evaluation of bidding item s and the auction mechanism comprising of the _allocation rule _X_: _𝔅ⁿ → [0,1]ⁿ and _pricing rule _P_: _𝔅ⁿ → ℝⁿ. The utility function can thus be specified as follows:
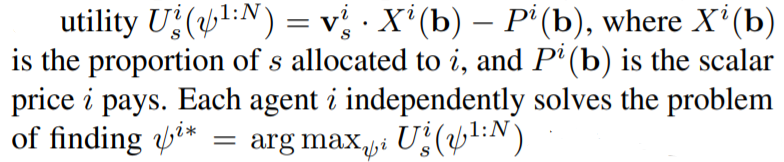
In auction theory, an auction is a _Dominant Strategy Incentive Compatible _(DSIC) if independent of other players’ bidding strategies in the auction, bidding on one’s evaluation is optimal. Vickrey auction [2], which sets Pᵢ(b) to the second-highest bid and Xᵢ(b)=1 if agent _i _wins and 0 respectively if agent _i _loses, is DSIC, meaning that the dominant strategy equilibrium happens when every agent bids truthfully. This results in maximizing social welfare ∑vᵢ×Xᵢ(b), hence choosing the bidder with the highest evaluation. The presence of DSIC property in _Vickrey auction _removes the need for agents to take into consideration other agents while performing their optimization, hence the decentralized reinforcement learning algorithm built using Vickrey auction operates non-cooperatively.
Definitions
_“A _primitive _(agent)__ω__is a tuple (ψ, ϕ), where ψ: S→𝔅 represents the bidding policy and ϕ: S→S represents the transformation. A __society _is a group of primitives denoted as ω^{1:N}.
Optimal bidding_ (as described in [3]): Assuming that at each state s the local auction allocates Xᵢ(b)=1 if agent i wins and Xᵢ(b)=0 if agent i loses. Then all primitives ω^i bidding their respective optimal societal Q-values as a whole produce an optimal global policy._
_Dominant Strategies for Optimal Bidding _(as described in [1]): If the valuations vᵢ for each state s are the most favourable societal Q-values, then the optimal global policy of the society coincides with the distinctive dominant strategy equilibrium of the primitives under the Vickrey mechanism.” — [1]
Economic Transactions Perspective
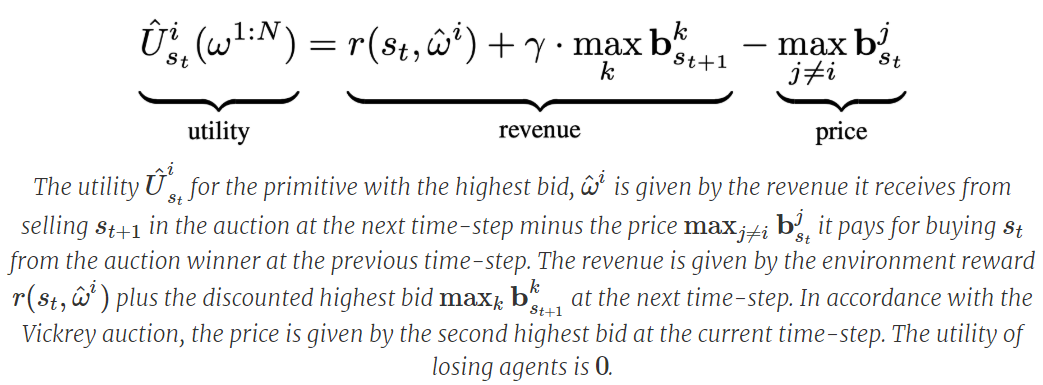
Market Economy Perspective with an explanation.
Hence, currency in the above system is grounded in the rewards received and wealth distribution happens depending on what future primitives decide to bid for the fruits of the labour of information processing undertaken by past primitives with the aim of transforming one state to another.
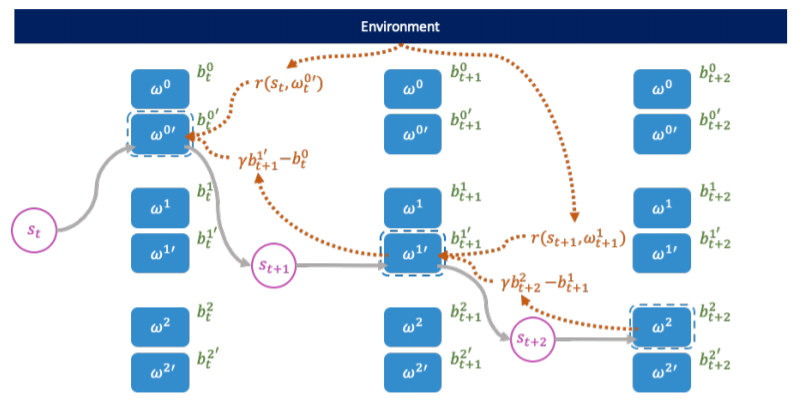
The cloned Vickrey society. Source Figure 1 in [1]

A succinct explanation of the preceding figure describing the clove Vickrey society mechanism. Source: Figure 1 in [1]
On-Policy Decentralized Reinforcement Learning Algorithm

After learning the inner-workings of the decentralized reinforcement learningalgorithm utilizing the cloned Vickrey auction mechanism, if you want to know more about the experiments performed using the algorithm please refer Section 7 titled Experiments of [1].
#data-science #decentralization #deep-learning #deep learning