Microservices architecture doesn’t require an introduction. It has been widely adopted in recent years by many companies in various domains and sizes. Some companies have redesigned their monolith architecture and broke it up to microservices, while others have built it up from the ground up as a pure microservices architecture.
In any case, a true microservices platform requires each service to be responsible for its own data (also known as isolated persistence or decentralized data management). This concept is implemented by the database-per-service pattern, which means that each microservice should have its own private database instance, collections or tables that are not shared with other services.
If we allow database sharing between microservices, it means that our data model is managed by multiple services, making it hard to guarantee consistency and invariance. All the other services should either request the data through the API of the responsible service or keep a read-only non-canonical (maybe materialized) copy of it.
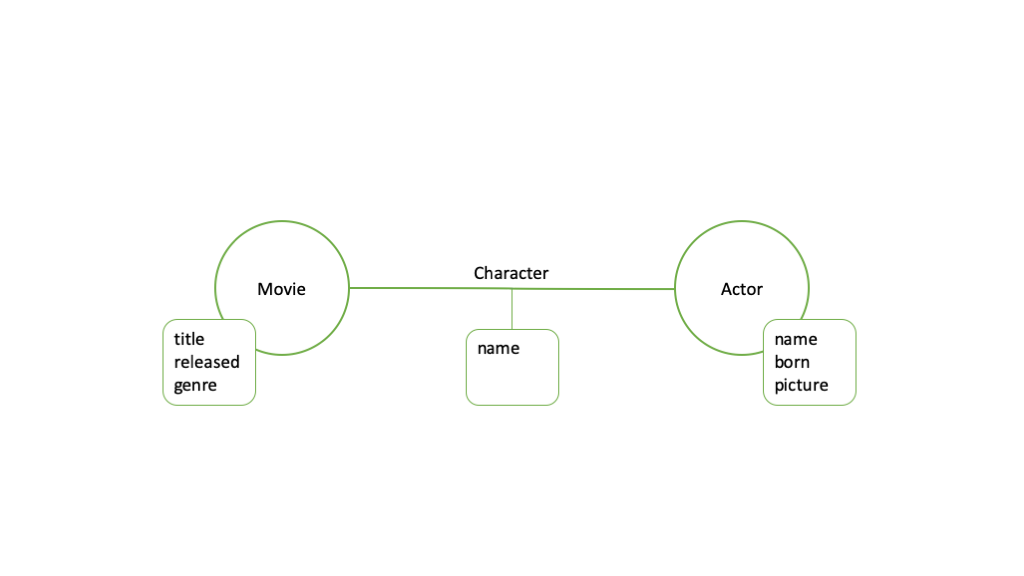
Now, let’s start with a contrived example, which is often being used in the context of graph databases. In our data model we have movies and actors and we want to describe the relations between them: for each movie we want to know the cast, and for each actor we want to know their filmography. This is a simplified version of the online Internet Movie Database, which is well known as IMDb.com. Also, for simplicity we will just store for each movie its title, genre and release year. Similarly, for actors we will store their name, picture URL and year of birth. In addition, we also want to store the name of the character that every actor played in each movie.
With this simple data model, our microservices architecture is straight forward. We probably need one microservice for managing movies and another one for actors. Following the database-pre-service pattern that was introduced earlier, we will need a database collection for movies and a separate collection for actors. If we choose a document DB (like MongoDB or Couchbase), our movie data model would like the following example:
{
“id”: “m1”,
“title”: “The Matrix”,
“released”: 1999,
“genre”: “Sci-Fi”,
“actors”: [{
“actor_id”: “a1”,
“actor_name”: “Keanu Reeves”,
“character”: “Neo”
}, {
“actor_id”: “a2”,
“actor_name”: “Laurence Fishburne”,
“character”: “Morpheus”
}, {
“actor_id”: “a3”,
“actor_name”: “Carrie-Anne Moss”,
“character”: “Trinity”
}]
}
#microservice-architecture #microservices #software-architecture #graph-database #software-design