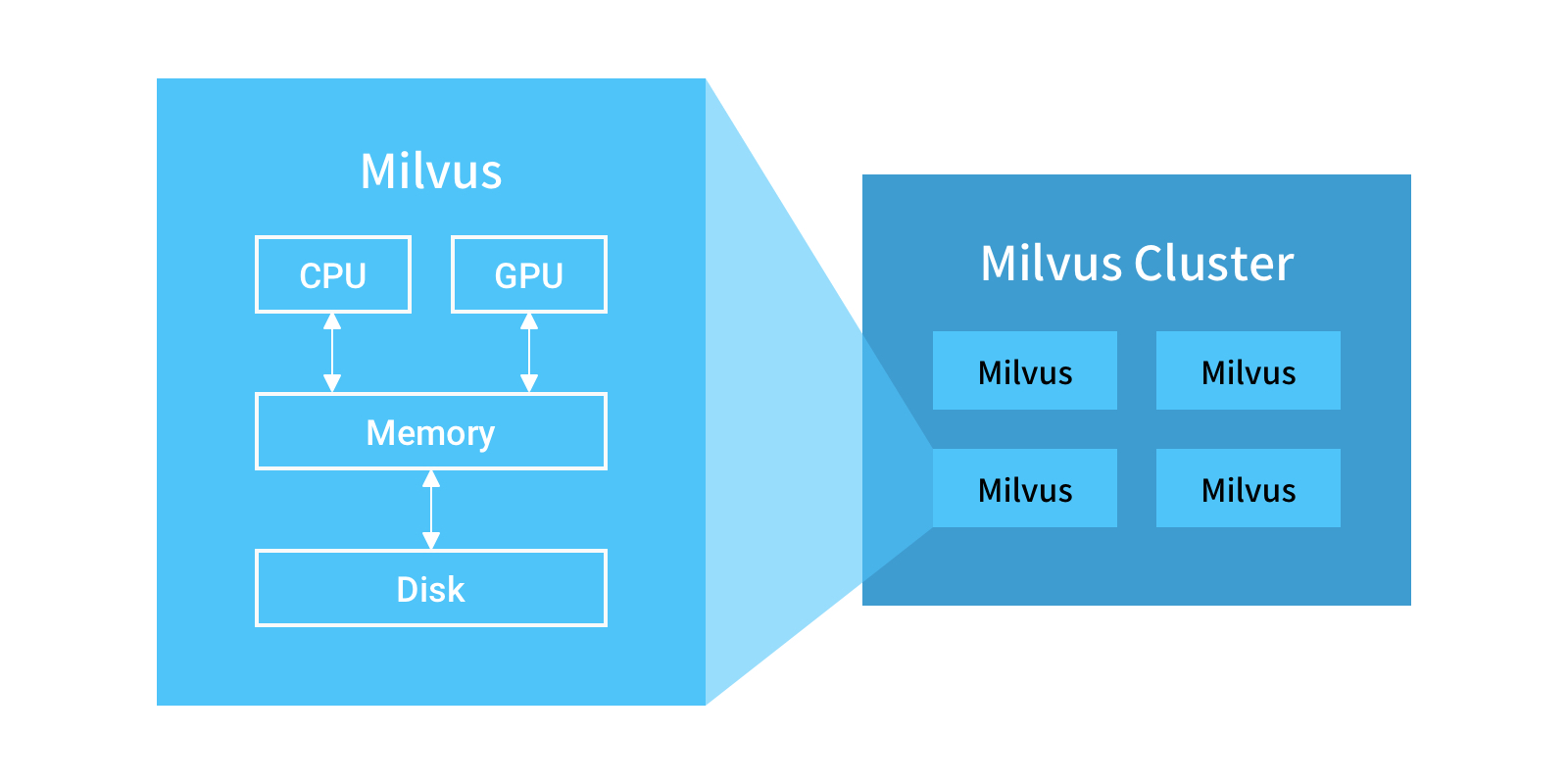
Milvus aims to achieve efficient similarity search and analytics for massive-scale vectors. A standalone Milvus instance can easily handle vector search for billion-scale vectors. However, for 10 billion, 100 billion or even larger datasets, a Milvus cluster is needed. The cluster can be used as a standalone instance for upper-level applications and can meet the business needs of low latency, high concurrency for massive-scale data. A Milvus cluster can resend requests, separate reading from writing, scale horizontally, and expand dynamically, thus providing a Milvus instance that can expand without limit. Mishards is a distributed solution for Milvus.
This article will briefly introduce components of the Mishards architecture. More detailed information will be introduced in the upcoming articles.
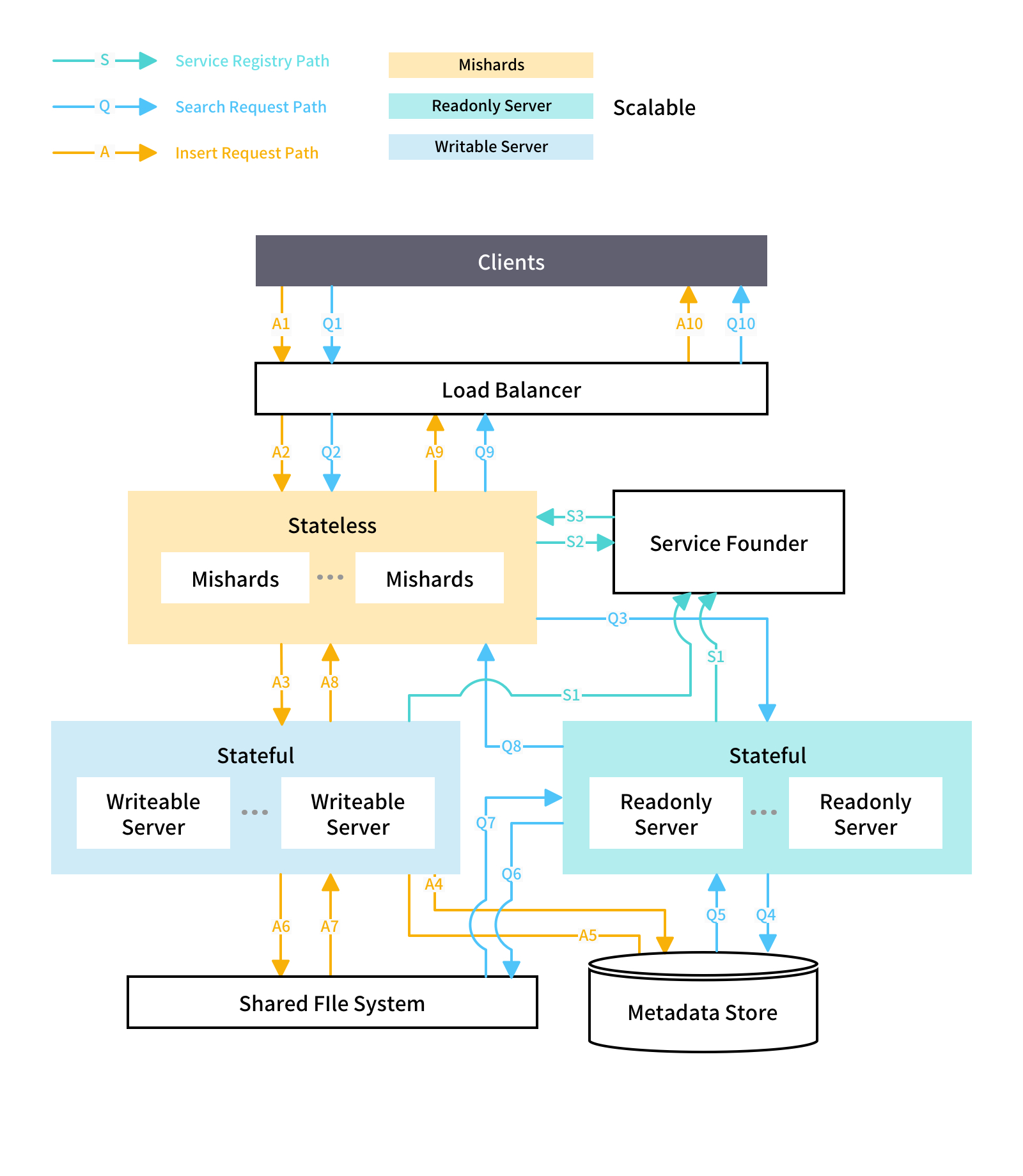
Distributed Architecture Overview
Service Tracing
Primary Service Components
- Service discovery framework, such as ZooKeeper, etcd, and Consul
- Load balancer, such as Nginx, HAProxy, Ingress Controller
- Mishards node: stateless, scalable
- Write-only Milvus node: single node and not scalable. You need to use high availability solutions for this node to avoid single-point-of-failure
- Read-only Milvus node: Stateful node and scalable
- Shared storage service: All Milvus nodes use shared storage service to share data, such as NAS or NFS
- Metadata service: All Milvus nodes use this service to share metadata. Currently, only MySQL is supported. This service requires MySQL high availability solution
Scalable Components
- Mishards
- Read-only Milvus nodes
Components Introduction
Mishards Nodes
Mishards is responsible for breaking up upstream requests and routing sub-requests to sub-services. The results are summarized to return to upstream.
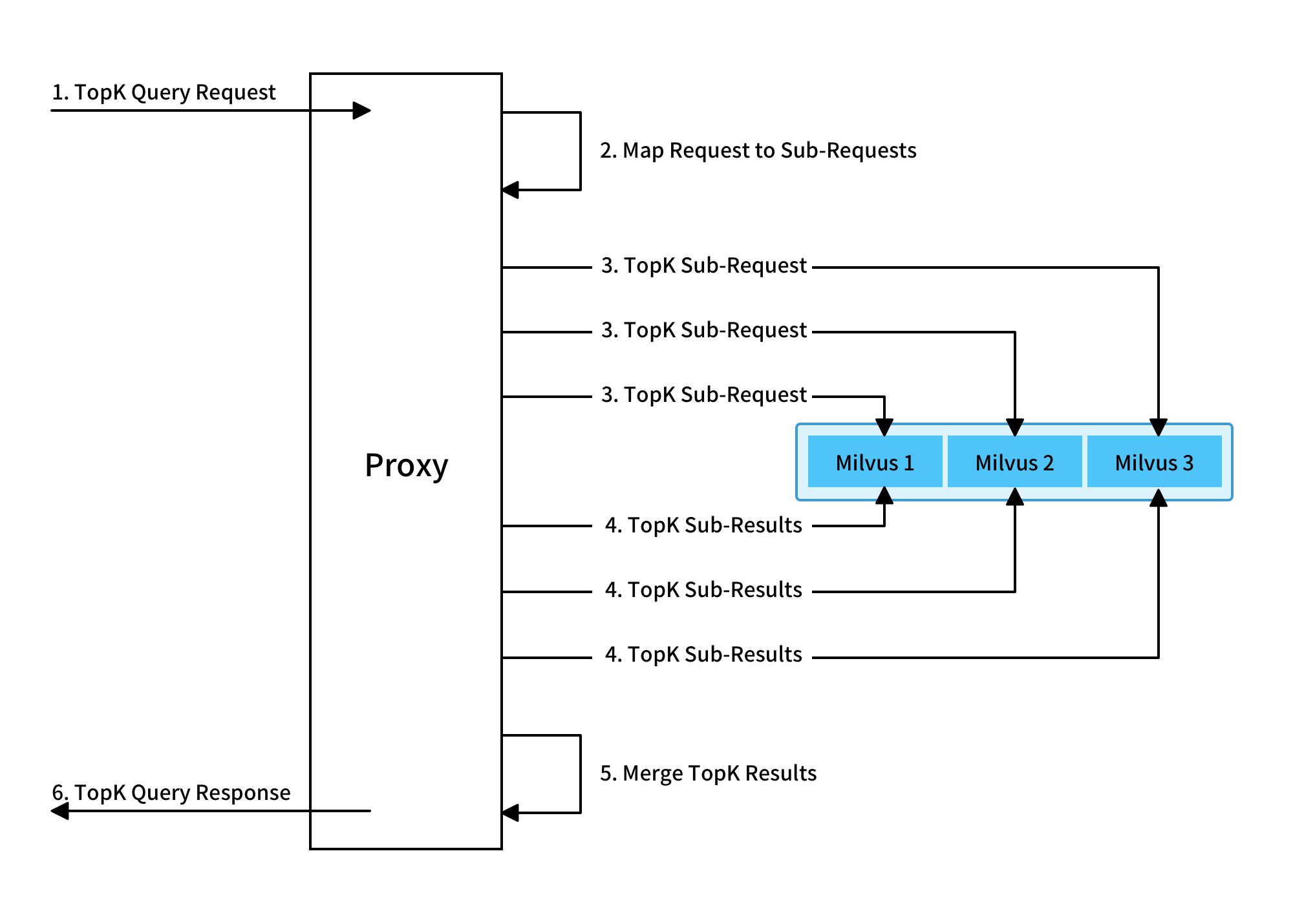
As is indicated in the chart above, after accepting a TopK search request, Mishards first breaks up the request into sub-requests and send the sub-requests to the downstream service. When all sub-responses are collected, the sub-responses are merged and returned to upstream.
Because Mishards is a stateless service, it does not save data or participate in complex computation. Thus, nodes do not have high configuration requirements and the computing power is mainly used in merging sub-results. So, it is possible to increase the number of Mishards nodes for high concurrency.
#mysql #nginx #data management #zookeeper #sharding #prometheus #distributed architecture #opentracing #etcd
