In this post, you will learn
- How are the CPU and GPU resources used in a naive approach during model training?
- How efficiently use the CPU and GPU resources for data pre-processing and training?
- Why use tf.data to build an efficient input pipeline?
- How to build an efficient input data pipeline for images using tf.data?
How does a naive approach work for input data pipeline and model training?
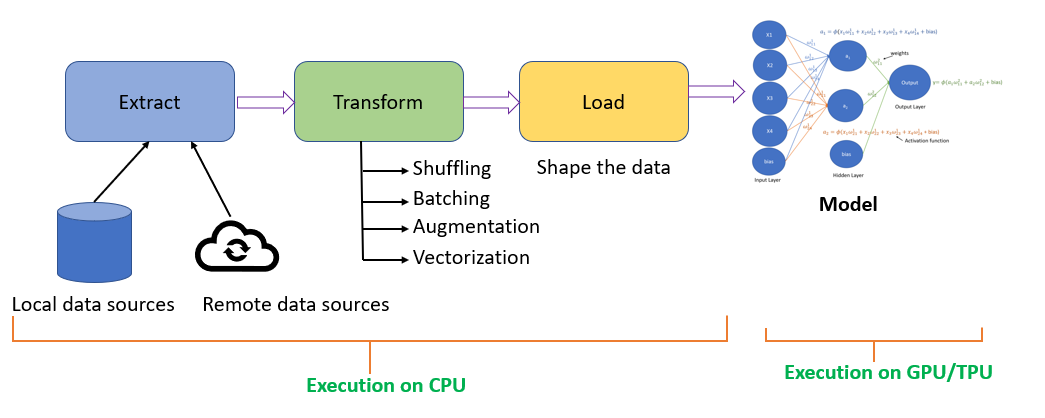
When creating an input data pipeline, typically, we perform the ETL(Extract, Transform, and Load) process.
- Extraction, extract the data from different data sources like local data sources, which can be from a hard disk or extract data from remote data sources like cloud storage.
- Transformation, you will shuffle the data, creates batches, apply vectorization or image augmentation.
- Loading the data involves cleaning the data and shaping it into a format that we can pass to the deep learning model for training.
The pre-processing of the data occurs on the CPU, and the model will be typically trained on GPU/TPU.
In a naive model training approach, CPU pre-processes the data to get it ready for the model to train, while the GPU/TPU is idle. When GPU/TPU starts training the model, the CPU is idle. This is not an efficient way to manage resources as shown below.
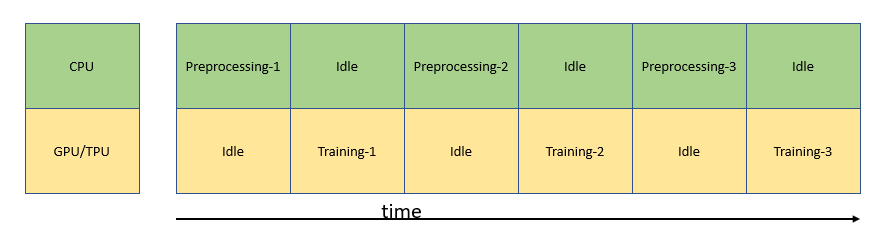
Naive data pre-processing and training approach
What are the options to expedite the training process?
To expedite the training, we need to optimize the data extraction, data transformation, and data loading process, all of which happens on the CPU.
Data Extraction: Optimize the data read from data sources
Data Transformation: Parallelize the data augmentation
Data Loading: Prefetch the data one step ahead of training
These techniques will efficiently utilize the CPU and GPU/TPU resources for data pre-processing and training.
How can we achieve the input pipeline optimization?
#image-classification #model-optimization #tensorflow #machine-learning #deep-learning