The basic idea of human pose estimation is understanding people’s movements in videos and images. By defining keypoints (joints) on a human body like wrists, elbows, knees, and ankles in images or videos, the deep learning-based system recognizes a specific posture in space. Basically, there are two types of pose estimation: 2D and 3D. 2D estimation involves the extraction of X, Y coordinates for each joint from an RGB image, and 3D - XYZ coordinates from an RGB image.
In this article, we explore how 3D human pose estimation works based on our research and experiments, which were part of the analysis of applying human pose estimation in AI fitness coach applications.
How 3D Human Pose Estimation Works
The goal of 3D human pose estimation is to detect the XYZ coordinates of a specific number of joints (keypoints) on the human body by using an image containing a person. Visually 3D keypoints (joints) are tracked as follows:
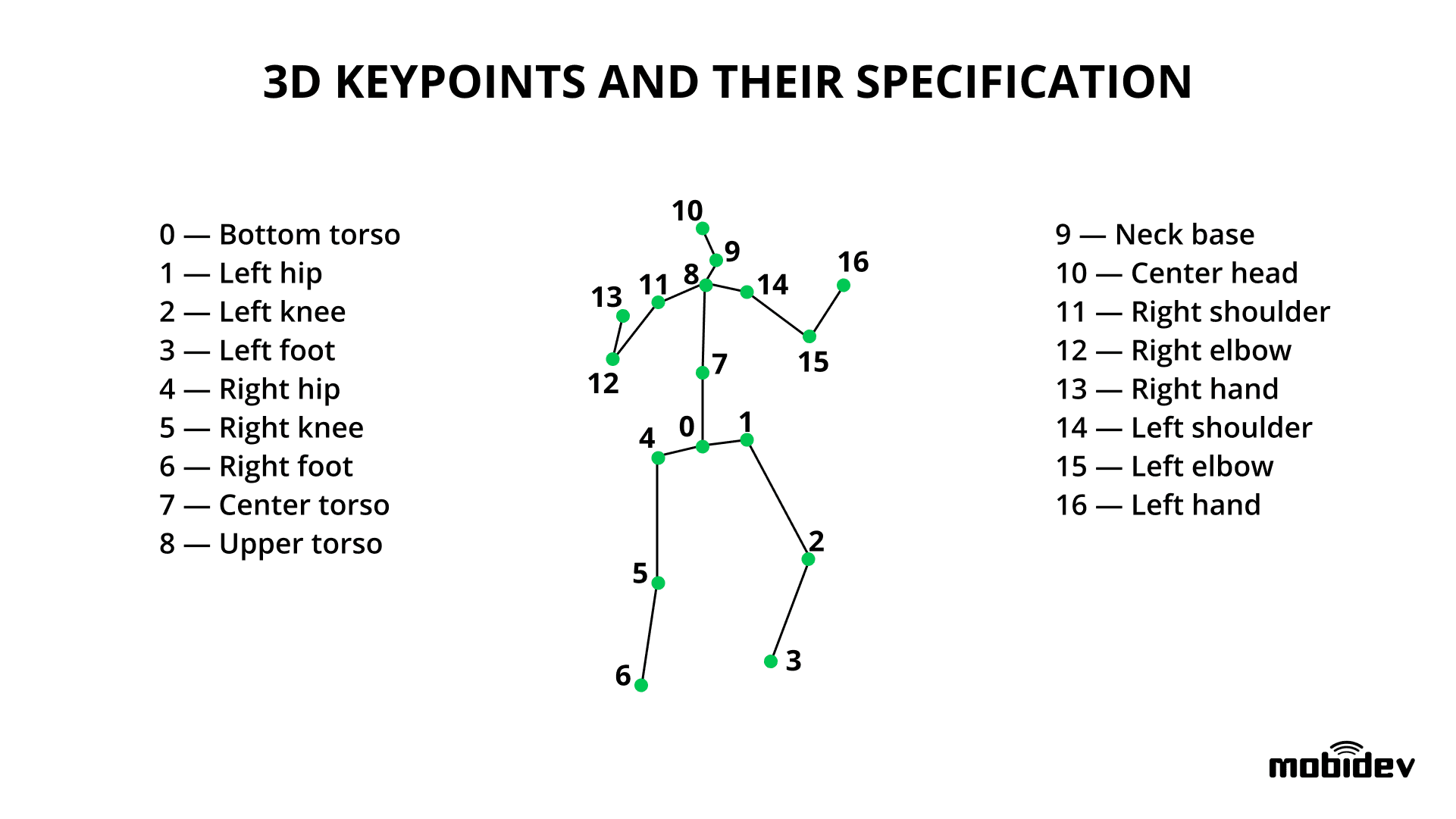
3D keypoints and their specification (https://mobidev.biz/wp-content/uploads/2020/07/3d-keypoints-human-pose-estimation.png)
Once the position of joints is extracted, the movement analysis system checks the posture of a person. When keypoints are extracted from a sequence of frames of a video stream, the system can analyze the person’s actual movement.
There are multiple approaches to 3D human pose estimation:
- To train a model capable of inferring 3D keypoints directly from the provided images.
- For example, a multi-view model EpipolarPose is trained to jointly estimate the positions of 2D and 3D keypoints. The interesting thing is that it requires no ground truth 3D data for training - only 2D keypoints. Instead, it constructs the 3D ground truth in a self-supervised way by applying epipolar geometry to 2D predictions. It is helpful since a common problem with training 3D human pose estimation models is a lack of high-quality 3D pose annotations.
- To detect the 2D keypoints and then transform them into 3D.
- This approach is the most common because 2D keypoint prediction is well-explored and usage of a pre-trained backbone for 2D predictions increases the overall accuracy of the system. Moreover, many existing models provide decent accuracy and real-time inference speed (for example, PoseNet, HRNet, Mask R-CNN, Cascaded Pyramid Network).
#2020 aug tutorials # overviews #analysis #computer vision #humans #sports #video recognition