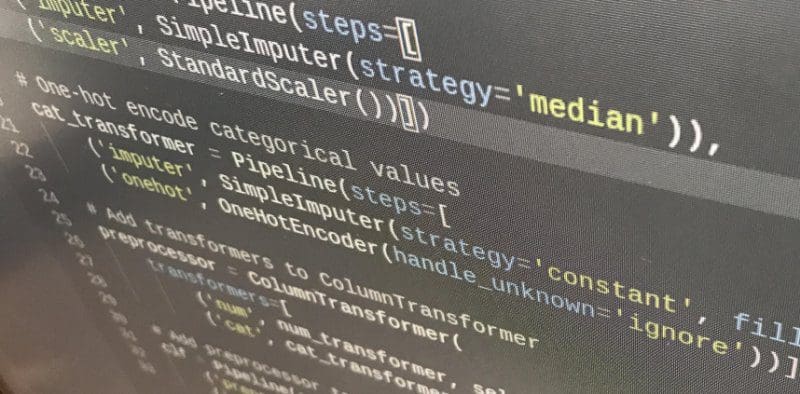
There is a quick and easy way to perform preprocessing on mixed feature type data in Scikit-Learn, which can be integrated into your machine learning pipelines.
Let’s say we want to perform mixed feature type preprocessing in Python. For our purposes, let’s say this includes:
scaling of numeric values
transforming of categorical values to one-hot encoded
imputing all missing values
Let’s further say that we want this to be as painless, automated, and integrated into our machine learning workflow as possible.
In a Python machine learning ecosystem, previously this could have been accomplished with a mix of directly manipulating Pandas DataFrames and/or using Numpy ndarray operations, perhaps alongside some Scikit-learn modules, depending on one’s preferences. While these would still be perfectly acceptable approaches, this can now also all be done in Scikit-learn alone. With this approach, it can be almost fully automated, and it can be integrated into a Scikit-learn pipeline for seamless implementation and easier reproducibility.
#2020 jun tutorials # overviews #data preprocessing #pipeline #python #scikit-learn