Introduction
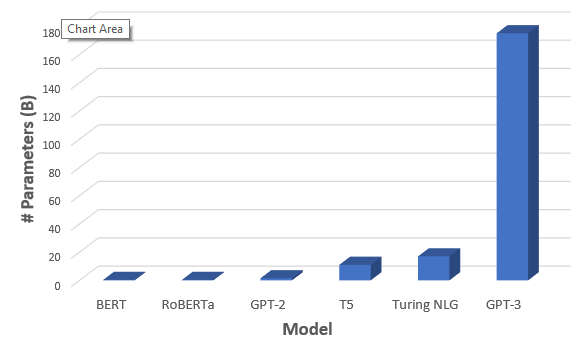
OpenAI recently released pre-print of its new mighty language model GPT-3. Its a much bigger and better version of its predecessor GPT-2. In fact, with close to 175B trainable parameters, GPT-3 is much bigger in terms of size in comparison to anything else out there. Here is a comparison of number of parameters of recent popular pre trained NLP models, GPT-3 clearly stands out.
What’s New?
After the success of Bert, the field of NLP is increasingly moving in the direction of creating pre-trained language models, trained on huge text corpus (in an unsupervised way), which are later fine-tuned on specific tasks such as translation, question answering etc using much smaller task specific datasets.
While this type of transfer learning obviates the need to use task specific model architectures, but you still need task specific datasets, which are a pain to collect, to achieve good performance.
Humans by contrast learn in a very different way, and have the ability to learn a new task based on very few examples. GPT-3 aims to address this specific pain point, that is, its a task agnostic model, which needs zero to very limited examples to do well and achieve close to state of the art performance on a number of NLP tasks
Terminologies
Before we deep dive, it may be useful to define some commonly used terminologies:
- **NPL Tasks: **These are tasks which have something to do with human languages, example — Language Translation, Text Classification (e.g. Sentiment extraction), Reading Comprehension, Named Entity Recognition (e.g. recognizing person, location, company names in text)
- Language Models: These are models which can predict the most likely next words (and their probabilities) given a set of words (think something like Google query auto-complete). Turns out these type of models are useful for a host of other tasks although they may be trained on mundane next word prediction
- **Zero / One / Few shot learning: **Refers to model’s ability to learn a new task by seeing zero / one / few examples for that task
- **Transfer Learning: **Refers to the notion in Deep Learning where you train a model for one task (example object detection in images) , but the ability to leverage and build upon that for some other different task (example assessing MRI scans). After massive success in Computer Vision, its in vogue in NLP these days.
- Transformer Models: Deep learning family of models, used primarily in NLP, which forms the basic building block of most of the state-of-the-art NLP architectures these days. You can read more about Transformers at one of my earlier blog
#nlp #data-science #deep-learning #data analysis