What is Support Vector Regression (SVR)?
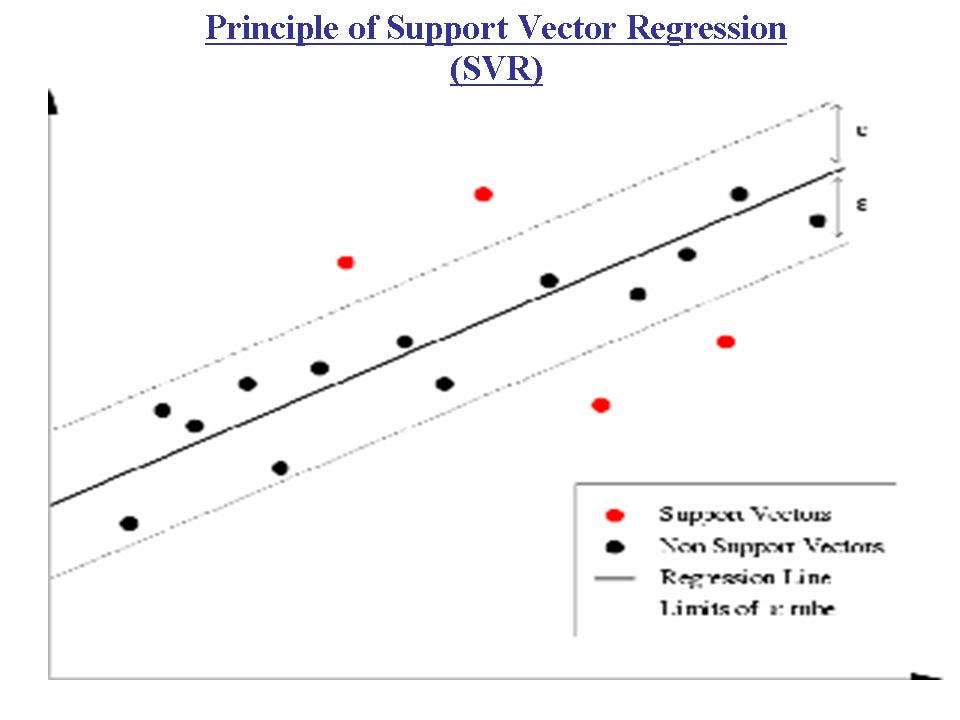
Support Vector Regression(SVR) is quite different than other Regression models. It uses the Support Vector Machine(SVM, a classification algorithm) algorithm to predict a continuous variable. While other linear regression models try to minimize the error between the predicted and the actual value, Support Vector Regression tries to fit the best line within a predefined or threshold error value.
What SVR does in this sense is that it tries to classify all the prediction lines in two types, ones that pass through the error boundary (space separated by two parallel lines) and ones that don’t. Those lines which do not pass the error boundary are not considered as the difference between the predicted value and the actual value has exceeded the error threshold, 𝞮(epsilon). The lines that pass, are considered for a potential support vector to predict the value of an unknown. The following illustration will help you to grab this concept.
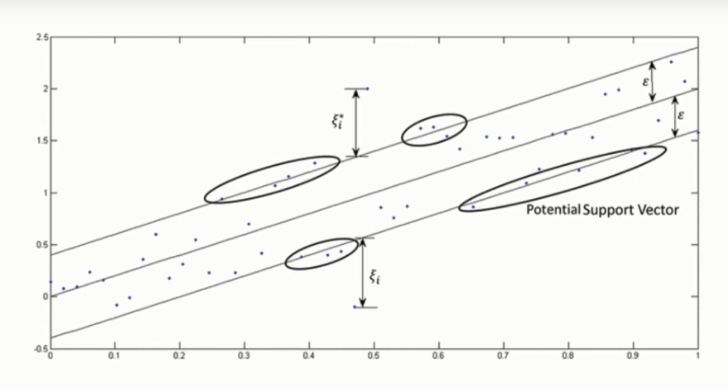
Support Vector Regression
For a fact we know that, as in classification, support vector regression (SVR) is characterized by the use of kernels, sparse solution, and VC control of the margin and the number of support vectors. Although less popular than SVM, SVR has been proven to be an effective tool in real-value function estimation.
:
#support-vector-regression #deep-learning #data analysis