The Goal
The API will allow us to do the following:
- Save podcasts (name and URL) in a cloud database.
- Query all of our saved podcasts.
- Update & Delete the saved podcasts.
Setup
In a directory of your choice, create a folder to house the application and navigate to it.
mkdir graphql-medium
cd graphql-medium
Initialise the project with npm.
npm init
Running npm init creates a package.json file for us. This file details information about the project, such as its name, its dependencies and the different scripts associated with it.
We define a start-script to let us easily run the application. We want to make sure to call it “start” because when we deploy our API later on, Heroku will be specifically looking for this script.
Using nodemon, our application is automatically refreshed every time we make a change to the code. This saves us development time as we do not have to manually restart the server to test every little change.
Add nodemon to the project.
npm i nodemon
Now add a start script to package.json.
"scripts": {
"start": "nodemon src/index.js"
}
Project Structure
We’ve told our start script to look for a file called **index.js **in a folder called **src. **This index file will be the main file in our project. It’s where we will define the logic to run the API server.
This is the project structure that I will be using. I’ll explain what lives in each folder.
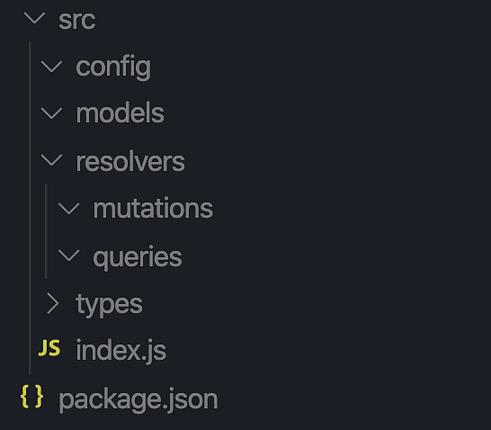
src/types
Graphql uses a **type **system to describe the nature and the shape of data. One can create as many **types **as is necessary for a system. For example, this is how the **type **of our podcast data will look.
type Podcast {
id: ID!
name: String!
url: String!
}
In English, this defines a type with the arbitrary name of Podcast. It is made up of three subfields, an id of type ID (which is a built-in type in GraphQL), and a name and URL both of type String. The exclamation mark states that is a required field.
src/resolvers
When a request is made to our API, it is the job of the resolvers to take the request and create an appropriate response. There are two types of requests one can make to a GraphQL API. Either you want to query (get)some data or you want to** mutate** (create/update/delete)some data.
The resolvers which house the logic to query our API will live in src/resolvers/queries and the resolvers used to mutate data will live in src/resolvers/mutations.
src/models
When we want to persist data into a database, such as MongoDB, we create a model to define how the data looks and how it should be stored. We will store the Podcast model in this folder.
src/config
The config folder will hold the logic to connect our server to a MongoDB database.
#javascript #graphql #nodejs #graphql api #api
