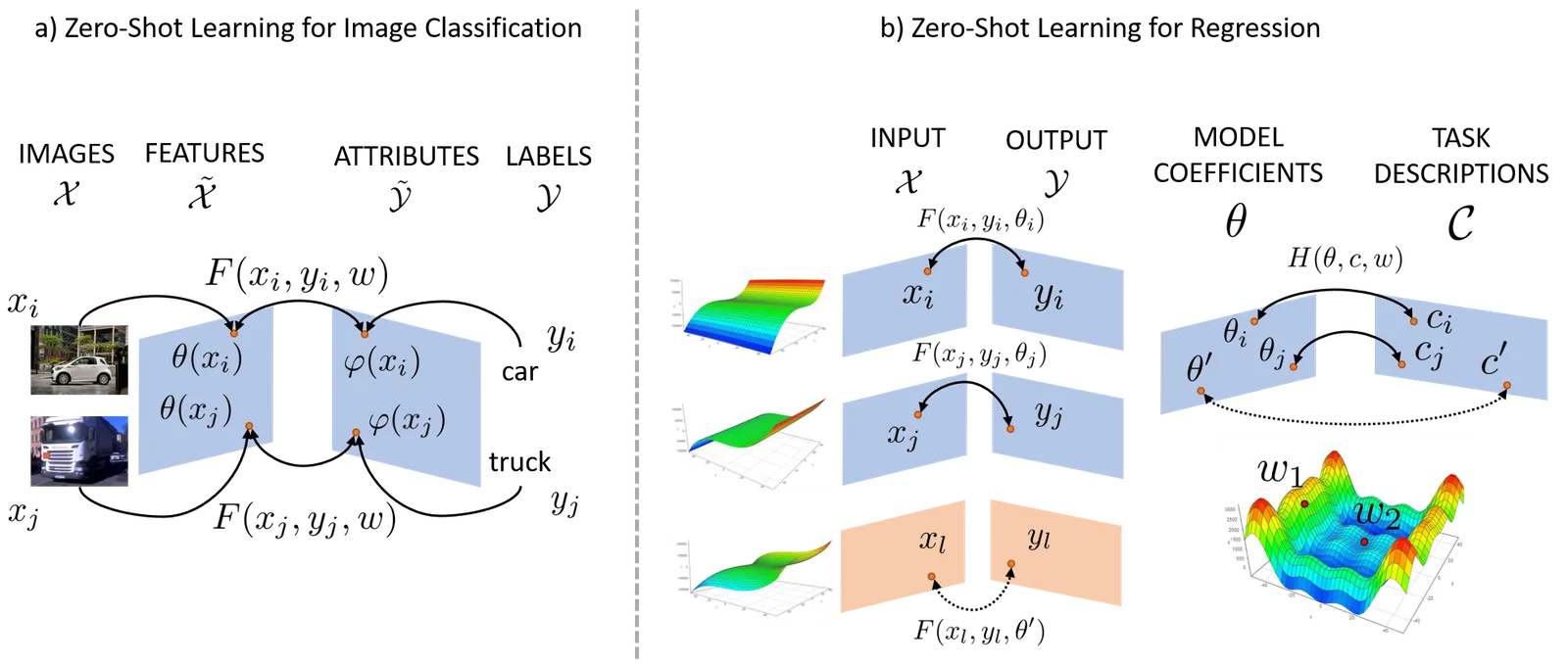
In this article, I would like to explain and practically demonstrate an area of machine learning called zero-shot learning, which I find really fascinating. Let’s start with a little description of what it actually is:
Zero-shot learning is a method of recognising categories, which have not been observed during training.
Compared to the traditional supervised learning approach, which relies on tons of examples for every category, the main idea of zero-shot learning is based on the semantic transfer from observed categories to the newly seen categories.
Imagine that you have never seen the letter “H” in your life. What if I told you that it consists of two vertical lines connected with a horizontal line in the middle? Would you be able to recognise it?

10 out of 15 manually designed features. Image by Author.
The key to such a semantic transfer is to encode categories as vectors in a semantic space. This is needed for both training and testing categories, and can be done in a supervised or an unsupervised way.
A supervised way would to manually annotate the categories by coming up with some features e.g. a dog = has tail, has fur, four legs etc. and encoding them into category vectors. The features could be also taken from already existing taxonomies in the given field.
An unsupervised way would be to use the word embeddings for the category names. This is because the word embeddings already capture semantic meaning of the categories, according to the context that the category names appeared in the text (e.g. in the wikipedia corpus).
#data-science #machine-learning #convolutional-network #zero-shot-learning #computer-vision