Problem Statement
Training deep neural networks can be a challenging task, especially for very deep models. A major part of this difficulty is due to the instability of the gradients computed via backpropagation. In this post, we will learn **how to create a self-normalizing deep feed-forward neural network using Keras. **This will solve the gradient instability issue, speeding up training convergence, and improving model performance.
Disclaimer: This article is a brief summary with focus on implementation. Please read the cited papers for full details and mathematical justification (link in sources section).
Background
In their 2010 landmark paper, Xavier Glorot and Yoshua Bengio provided invaluable insights concerning the difficulty of training deep neural networks.
It turns out the then-popular choice of activation function and weight initialization technique were directly contributing to what is known as the Vanishing/Exploding Gradient Problem.
In succinct terms, this is when the gradients start shrinking or increasing so much that they make training impossible.
Saturating Activation Functions
Before the wide adoption of the now ubiquitous ReLU function and its variants, sigmoid functions (S-shaped) were the most popular choice of the activation function. One such example of a sigmoid activation is the logistic function:
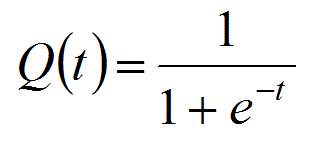
**Source: **https://www.mhnederlof.nl/logistic.html
**One major disadvantage of sigmoid functions is that they saturate. **In the case of the logistic function, the outputs saturate to either 0 or 1 for negative and positive inputs respectively. This leads to smaller and smaller gradients (_very _close to 0) as the magnitude of the inputs increases.
#neural-networks #ai #convergence #machine-learning #keras #deep-learning