Q -learning, as the name suggests, it’s a learning-based algorithm in reinforcement learning. Q-Learning is a basic form of Reinforcement Learning algorithm that uses Q-values (also called action values) to iteratively improve the behavior of the learning agent.
The main objective of Q-learning is to find the best optimal policy, discussed previously that maximizes the cumulative rewards (sum of all rewards). So, in other words, the goal of Q-learning is to find the optimal policy by learning the optimal Q-values for each state-action pair.
Q-Learning simplified with an example
Let’s consider a ROBOT who starts form the starting position (S) and its goal is to move the endpoint (G). This is a game: Frozen Lake where; S=starting point, F=frozen surface, H=hole, and G=goal. The robot can either move _f_orward, _d_ownward, _l_eft, _r_ight.
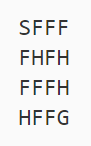
Robots win if reaches Goal and looses if falls in a Hole.

Thanks for gif:
Now, the obvious question is: How do we train a robot to reach the end goal with the shortest path without stepping on a hole?
Introduction to Q-TABLE
Q-Table is a simple lookup table where we calculate the maximum expected future rewards for future action at each state. Q-table is created as per the possible action the robot can perform. Q-table is initialized with null values.
Initial Q-table
Each Q-table score will be the maximum expected future reward that the robot will get if it takes that action at that state. This is an iterative process, as we need to improve the Q-Table at each iteration.
But the questions are:
- How do we calculate the values of the Q-table**?**
- Are the values available or predefined**?**
To learn each value of the Q-table, we use the** Q-Learning algorithm. **As we discussed in the earlier part, we use the Bellman Equation to find optimal values for the action-value pair.
As we start to explore the environment**,** the Q-function gives us better and better approximations by continuously updating the Q-values in the table.
#machine-learning #deep-learning #q-learning #deep learning
