Hello everyone! Welcome back to the part-2 of human emotion and gesture detector using Deep Learning. In case you haven’t already, check out part-1 here. In this article, we will be covering the training of our gestures model and also look at a way to achieve higher accuracy on the emotions model. Finally, we will create a final pipeline using computer vision through which we can access our webcam and get a vocal response from the models we have trained. Without further ado let’s start coding and understanding the concepts.

For training the gestures model, we will be using a transfer learning model. We will use VGG-16 architecture for training the model and exclude the top layer of the VGG-16. Then we will proceed to add our own custom layers to improve the accuracy and reduce the loss. We will try to achieve an overall high accuracy of about 95% on our gestures model as we have a fairly balanced dataset and using the techniques of image data augmentation and the VGG-16 transfer learning model this task can be achieved easily and also in fewer epochs comparatively to our emotions model. In a future article, we will cover how exactly the VGG-16 architecture works but for now let us proceed to analyze the data at hand and perform an exploratory data analysis on the gestures dataset similar to how we performed on the emotions dataset after the extraction of images.
EXPLORATORY DATA ANALYSIS (EDA):
In this next code block, we will look at the contents in the train folder and try to figure out the total number of classes, that we have for each of the categories for the gestures in the train folder.
Train:

We can look at the four sub-folders we have in the train1 folder. Let us visually look at the number of images in these directories.
Bar Graph:

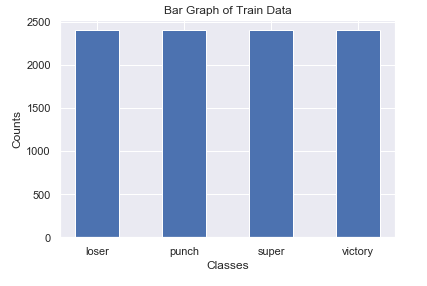
We can notice from the bar graph that each of the directories contains 2400 images each and this is a completely balanced dataset. Now, let us proceed to visualize the images in the train directory. We will look at the first image in each of the sub-directories and then look into the dimensions and number of channels of each of the images which are present in these folders.
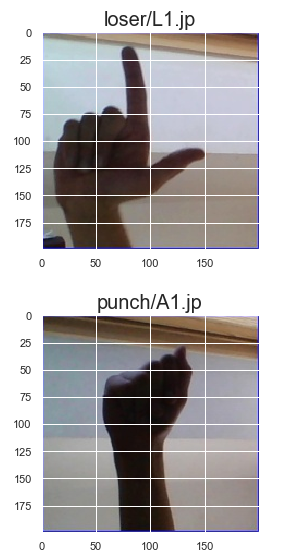
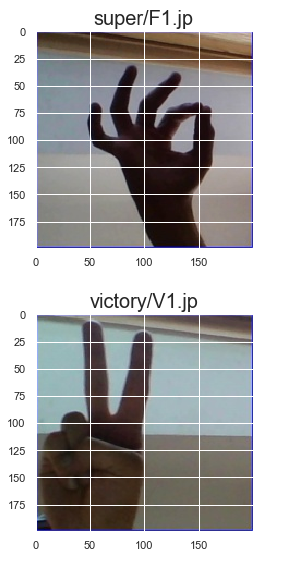
The dimension of the images are as follows:
The Height of the image = 200 pixels
The Width of the image = 200 pixels
The Number of channels = 3
Similarly, we can perform an analysis on the validation1 directory and check how our Validation dataset and the validation images look like.
#machine-learning #data-science #artificial-intelligence #deep-learning #emotion-gesture-detection #deep learning
