Time series problem
Time series forecasting is an intriguing area of Machine Learning that requires attention and can be highly profitable if allied to other complex topics such as stock price prediction. Time series forecasting is the application of a model to predict future values based on previously observed values.
By definition, a time series is a series of data points indexed in time order. _This type of problem is important because there is a variety of prediction problems that involve a time component, and finding the data/time relationship is key to the analysis (e.g. weather forecasting and earthquake prediction). However, these problems are neglected sometimes because modeling this time component relationship is not as trivial as it may sound.
Stock market prediction is the act of trying to determine the future value of a company stock. The successful prediction of a stock’s future price could yield a significant profit, and this topic is within the scope of time series problems.
Among the several ways developed over the years to accurately predict the complex and volatile variation of stock prices, neural networks, more specifically RNNs, have shown significant application on the field. Here we are going to build two different models of RNNs — LSTM and GRU — with PyTorch to predict Amazon’s stock market price and compare their performance in terms of time and efficiency.
Recurrent Neural Network (RNN)
A recurrent neural network (RNN) is a type of artificial neural network designed to recognize data’s sequential patterns to predict the following scenarios. This architecture is especially powerful because of its nodes connections, allowing the exhibition of a temporal dynamic behavior. Another important feature of this architecture is the use of feedback loops to process a sequence. Such a characteristic allows information to persist, often described as a memory. This behavior makes RNNs great for Natural Language Processing (NLP) and time series problems. Based on this structure, architectures called Long short-term memory (LSTM), and Gated recurrent units (GRU) were developed.
An LSTM unit is composed of a cell, an input gate, an output gate, and a forget gate. The cell remembers values over arbitrary time intervals, and the three gates regulate the flow of information into and out of the cell.
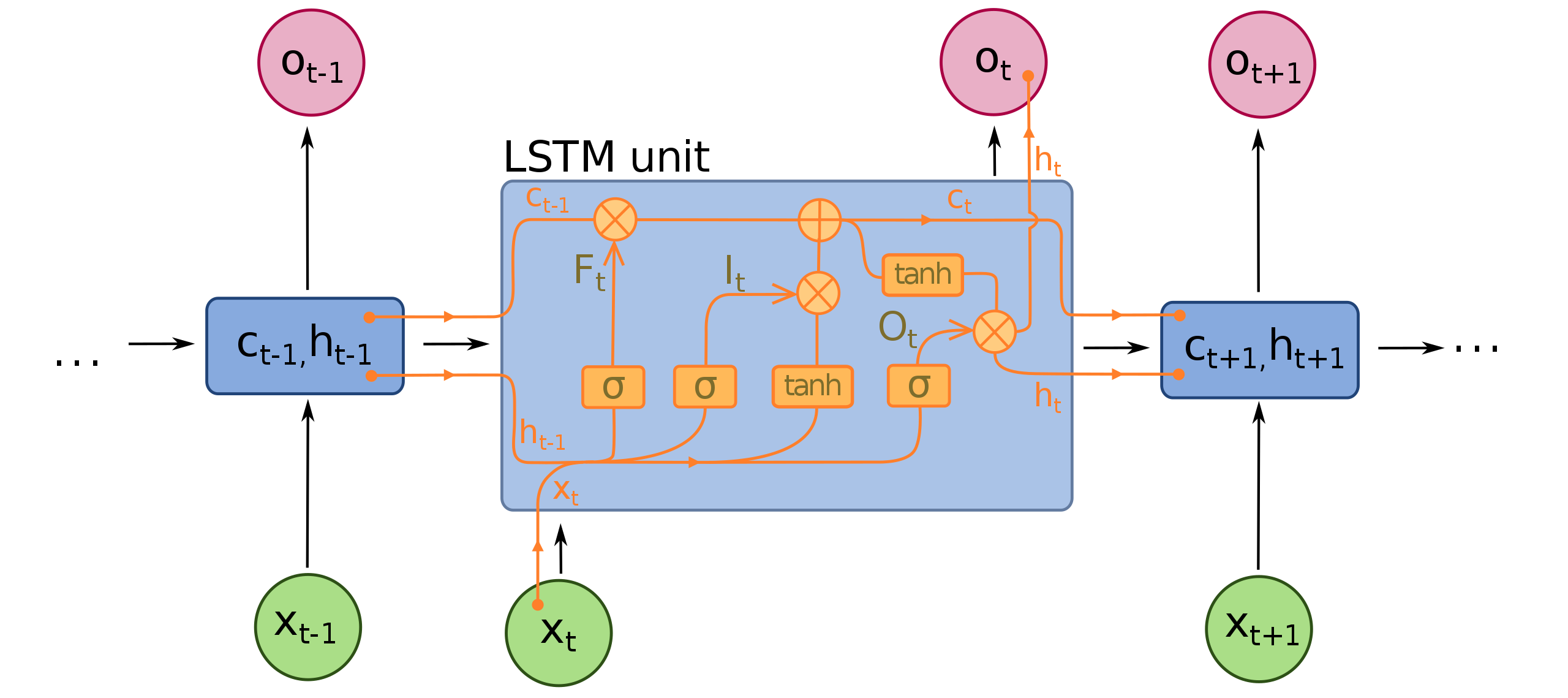
On the other hand, a GRU has fewer parameters than LSTM, lacking an output gate. Both structures can address the “short-term memory” issue plaguing vanilla RNNs and effectively retain long-term dependencies in sequential data.
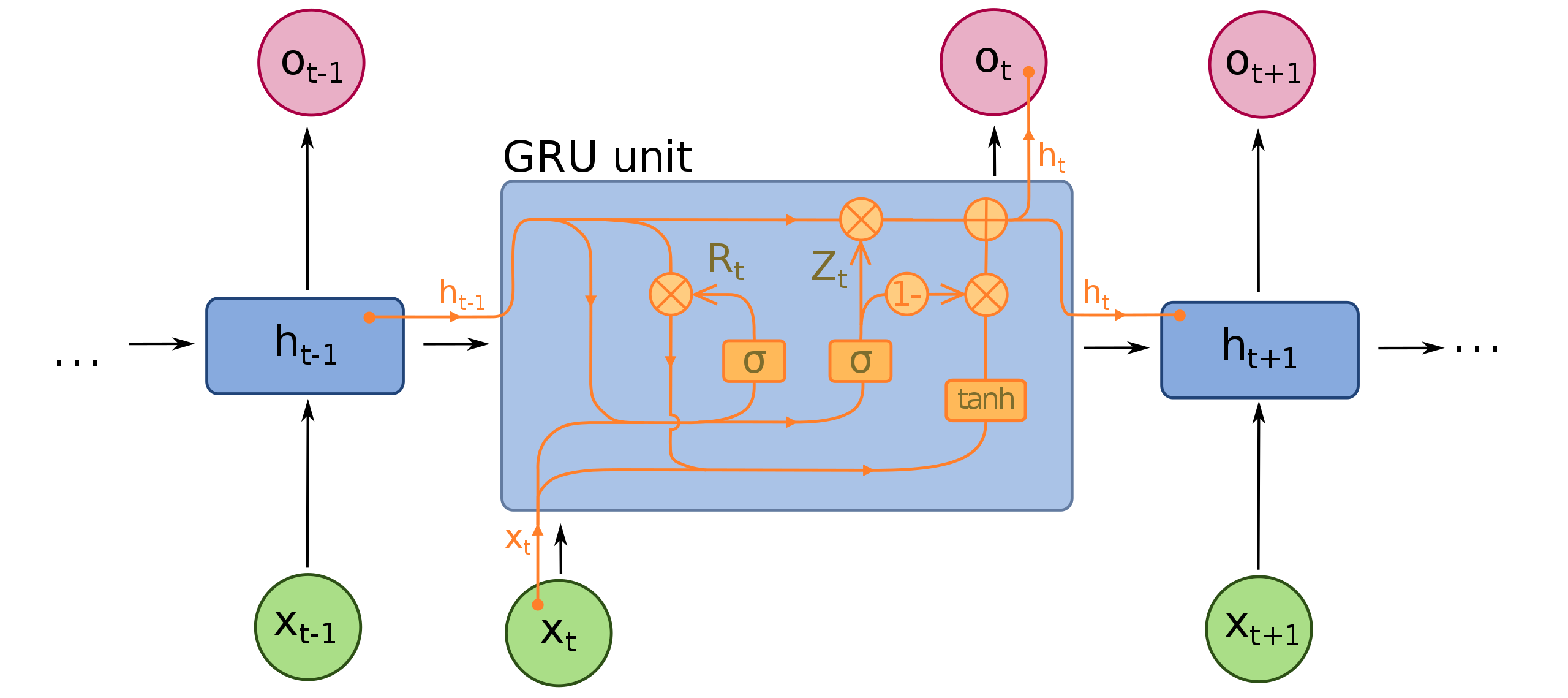
Although LSTM is currently more popular, the GRU is bound to eventually outshine it due to a superior speed while achieving similar accuracy and effectiveness. We are going to see that we have a similar outcome here, and the GRU model also performs better in this scenario.
#data-science #machine-learning #artificial-intelligence #deep-learning #neural-networks