As a data scientist, it’s valuable to have some idea of fundamental data warehouse concepts. Most of the work we do involves adding enterprise value on top of datasets that need to be clean and readily comprehensible. For a dataset to reach that stage of its lifecycle, it has already passed through many components of data architecture and, hopefully, many data quality filters. This is how we avoid the unfortunate situation wherein the data scientist ends up spending 80% of their time on data wrangling.
Let’s take a moment to deepen our appreciation of the data architecture process by learning about various considerations relevant to setting up a data warehouse.
The data warehouse is a specific infrastructure element that provides down-the-line users, including data analysts and data scientists, access to data that has been shaped to conform to business rules and is stored in an easy-to-query format.
The data warehouse typically connects information from multiple “source-of-truth” transactional databases, which may exist within individual business units. In contrast to information stored in a transactional database, the contents of a data warehouse are reformatted for speed and ease of querying.
The data must conform to specific business rules that validate quality. Then it is stored in a denormalized structure — that means storing together pieces of information that will likely be queried together. This serves to increase performance by decreasing the complexity of queries required to get data out of the warehouse (i.e., by reducing the number of data joins).
In this guide:
- Architecting the Data Warehouse
- Enhancing Performance and Adjusting Size
- Related Data Storage Options
- Working with Big Data
- Extract, Transform, Load (ETL)
- Getting Data out of the Warehouse
- Data Archiving
- Summary
Architecting the Data Warehouse
In the process of developing the dimension modelfor the data warehouse, the design will typically pass through three stages: (1) business model, which generalizes the data based on business requirements, (2) logical model, which sets the column types, and (3) physical model, which represents the actual design blueprint of the relational data warehouse.
Because the data warehouse will contain information from across all aspects of the business, stakeholders must agree in advance to the grain (i.e. level of granularity) of the data that will be stored.
Reminder to validate the model across various stakeholder groups before implementation.
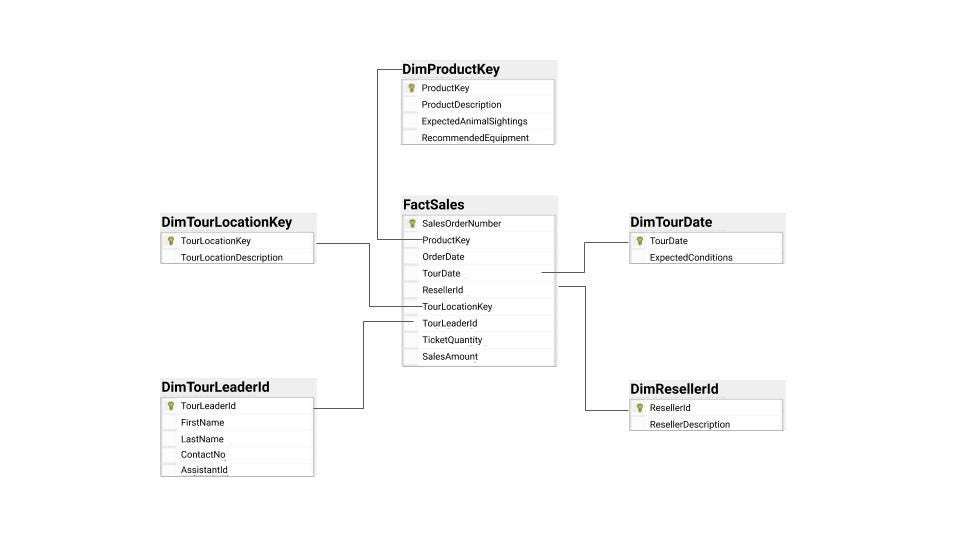
A sample star schema for a hypothetical safari tours business.
The underlying structure in the data warehouse is commonly referred to as the star schema — it classifies information as either a dimension or fact (i.e., measure). The fact table stores observations or events (i.e. sales, orders, stock balances, etc.) The dimension tables contain descriptive information about those facts (i.e. dates, locations, etc.)
There are three different types of fact tables: (1) transactional for records at the standardized grain, (2) periodic for records that fall within a given time frame, (3) cumulative for records that fall within a given business process.
In addition to the star schema, there’s also the option to arrange data into the snowflake schema. The difference here is that each dimension is normalized.
Normalization is a database design technique for creating records that contain an atomic level of information.
However, the snowflake schema adds unnecessary complexity to the dimension model — usually the star schema will suffice.
#database #data-warehouse #data #data-science #database-administration