上一篇簡單介紹機器學習後,這一篇要教大家使用Python強大的Scikit-Learn,它是一個單純而且有效率的資料探勘(data mining)和資料分析(data analysis)的工具。其中,Scikit-Learn在**獲取資料:sklearn.datasets、掌握資料:sklearn.preprocessing** 和 機器學習:sklearn Estimator API 三個面向提供支援。
獲取資料的方式有很多種(包含檔案、資料庫、網路爬蟲、Kaggle Datasets等),其中最簡單的方式是從Sklearn import 內建的資料庫。由於其特性隨手可得且不用下載,所以我們通常叫他**玩具資料**:
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.keys())
print(boston['filename'])



‘‘filename’’
先從datasets 使用 load_ 函數讀入一個像是dictionary的物件,像上圖中的load_boston 就有5組key-value組合。其中,‘filename’可以讓你去access這台電腦裡原始檔案的儲存位置,假如你想看一下它的原始檔案到底長什麼樣子,就可以把‘filename’秀出來。
掌握資料:Scikit-Learn表達資料的方式有分兩種:
特徵矩陣(Feature Matrix):m * n 的 ndarray
目標向量(Target Vector):m * 1 或是 (m, 1)的 ndarray
這邊將用kaggle-Getting Started 競賽的兩組訓練資料(train.csv)來示範如何擷出特徵矩陣 & 目標向量:
- Titanic 的目標向量為 Survived,其餘變數為特徵矩陣
- House Prices: Advanced Regression Techniques 的目標向量為 SalePrice,其餘變數為特徵矩陣
把 Titanic 資料讀進來之後,我們先用pandas把它轉換成表格,並用head()瀏覽表格的內容。題目告知Survived是目標向量後,我們要把這欄單獨切割出來,而表格中的其餘資料就是它的特徵矩陣。
import pandas as pd
titanic_url = "https://kaggle-getting-started.s3-ap-northeast-1.amazonaws.com/titanic/train.csv"
titanic_df = pd.read_csv(titanic_url)
titanic_df.head()

由於目前的資料是pandas的DataFrame的型態,所以我可以直接擷取我要的欄位。但是注意:我如果直接挑選欄位名稱,出來的資料型態會是Series。所以我最後要再加 .values 把值單獨取出來,資料才會變成向量的型態,最後也別忘了要reshape成欄位為1的形式。
y = titanic_df[['Survived']].values.reshape(-1, 1)
print(y)
那剩下的資料就是我的特徵矩陣咯,所以我這邊使用drop()函數刪掉 Survived 欄位後一樣取values。這邊要注意drop函數要記得給axis參數,因為它的預設參數是0,那他就會以row去看說有沒有一個row的index叫 ‘Survived’ 的,但我們這邊是要拿掉欄位,所以要記得給axis = 1。
X = titanic_df.drop('Survived', axis = 1).values
print(X)

就這樣,簡單的特徵矩陣和目標向量就被我們手動切割出來啦。
根據監督式學習(Supervised Learning)的定義:
使用標籤資料(labelled data)訓練模型,再對無標籤資料(unlabelled data)預測
所以我們可以使用
train.csv做訓練,然後對test.csv做預測對吧?
是,也不是。
為什麼答案是不一定呢?因為像是Kaggle 的 Getting Started 競賽允許一天上傳多次對答案。但在生活中的專案可沒有那麼多次機會讓你嘗試,你只能訓練模型,最後一直到testing_data出來了才能去做預測,那時候才知道自己的模型做的好不好(例如:A/B Test的實驗設計)。
因此,我們因此通常會將 train.csv 再切分成為訓練資料與驗證資料兩個部分:
訓練(training)是標籤資料(labelled data)
驗證(validation)是偽裝成無標籤資料(unlabelled data)的標籤資料(labelled data)
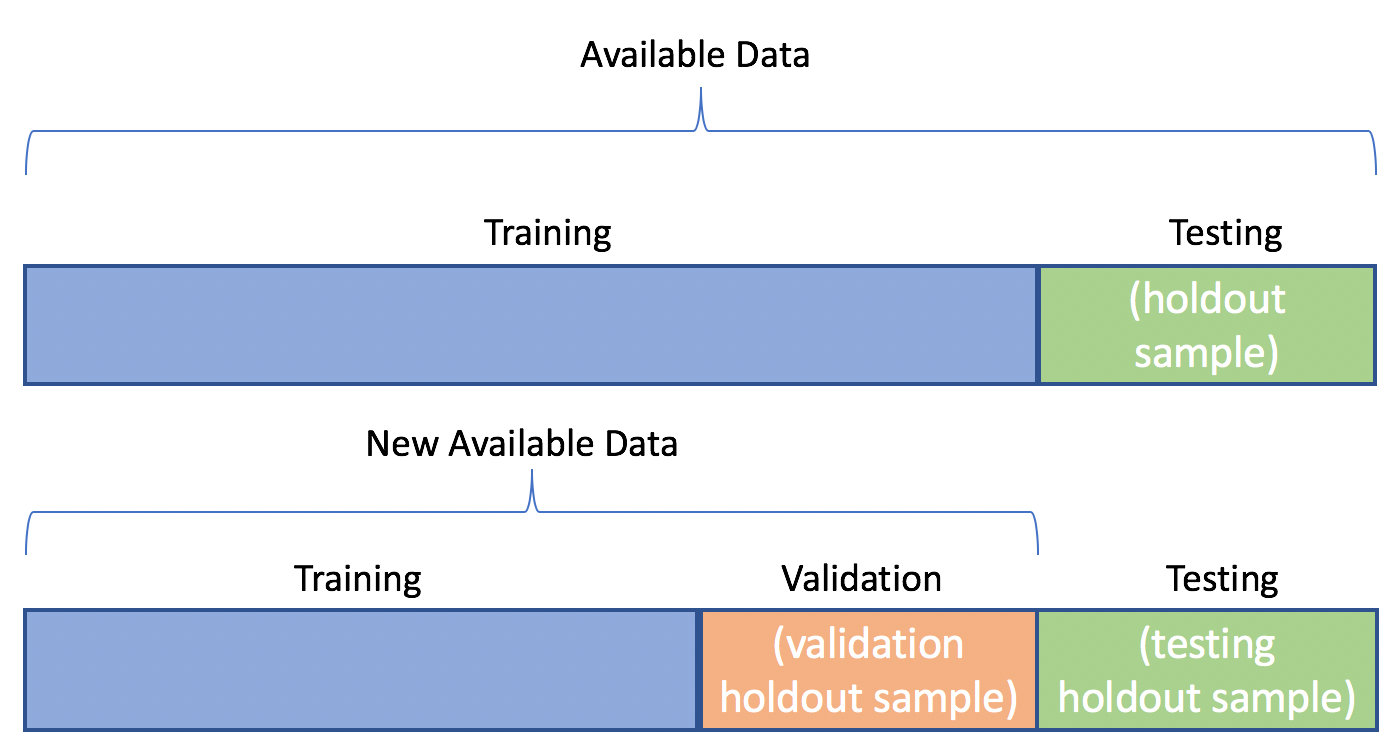
Scikit-Learn這裏就提供了一個非常好用的函式:我們可以使用_sklearn.model_selection_中的_train_test_split_函數。雖然說是train-test split,但實際上是train-validation split 。
#python #machine-learning