Loss functions are used to calculate the difference between the predicted output and the actual output. To know how they fit into neural networks, read :
Artificial Neural Networks: Explained
In this article, I’ll explain various loss functions for regression, their advantages, and disadvantages using which, you can select the right one for your project.
Let’s begin, shall we?
Loss functions are fundamentally dependent on the nature of our dependent variables and so, to select a loss function, we must examine if our dependent variables are numeric (in regression task) or probabilistic (in a classification task).
Loss functions for regression :
When we are dealing with numeric variables, we have to measure the losses numerically, meaning, just knowing if the predicted value is wrong is not enough, we have to calculate the amount of deviation of our prediction from the actual value, so we can train our network accordingly.
The different loss functions for this are :
- Mean Absolute Error (MAE).
- Mean Absolute Percentage Error (MAPE).
- Mean Squared Error (MSE).
- Root Mean Squared Error (RMSE).
- Huber Loss.
- Log-Cosh Loss.
Mean Absolute Error (MAE) :
MAE is the simplest error function, it literally just calculates the absolute difference (discards the sign) between the actual and predicted values and takes it’s mean.
Mathematical Equation :
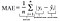
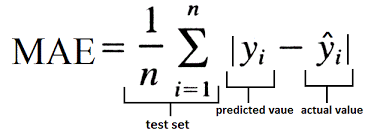
MAE Equation from Data Vedas
Graph :
The following figure shows that the MAE increases linearly with an increase in error.

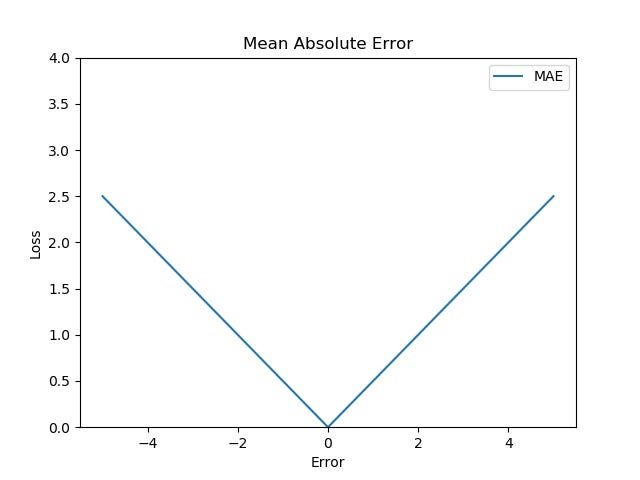
Image by author
Advantages :
- MAE is the simplest method to calculate the loss.
- Due to its simplicity, it is computationally inexpensive.
Drawbacks :
- MAE calculates loss by considering all the errors on the same scale. For example, if one of the output is on the scale of hundred while other is on the scale of thousand, our network won’t be able to distinguish between them just based on MAE, and so, it’s hard to alter weights during backpropagation.
- MAE is a linear scoring method, i.e. all the errors are weighted equally while calculating the mean. This means that while backpropagation, we may just jump past the minima due to MAE’s steep nature.
Mean Absolute Percentage Error (MAPE) :
MAPE is similar to that of MAE, with one key difference, that it calculates error in terms of percentage, instead of raw values. Due to this, MAPE is independent of the scale of our variables.
Mathematical Equation :
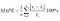
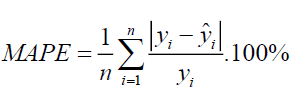
MAPE Equation from JIBC
Graph :
The following figure shows that the MAPE also increases linearly with an increase in error.

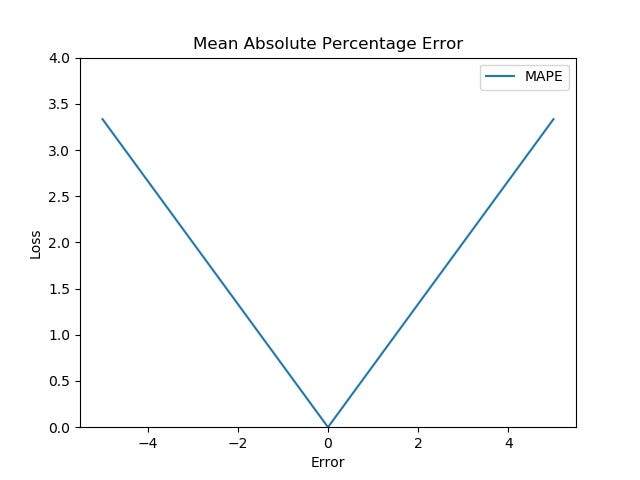
Image by author
Advantages :
- Loss is calculated by normalizing all errors on a common scale (of hundred).
Disadvantages :
- MAPE equation has the expected output in the denominator, which can be zero. Loss cannot be calculated for these, as division by zero is not defined.
- Again, division operation means that even for the same error, the magnitude of actual value can cause a difference in loss. For example, if the predicted value is 70 and the actual value is 100, the loss would be 0.3 (30%), while for the actual value of 40, the loss would be 0.75 (75%), even though the error in both the cases is the same, i.e. 30.
Mean Squared Error (MSE) :
In MSE, we calculate the square of our error and then take it’s mean. This is a quadratic scoring method, meaning, the penalty is proportional to not the error (like in MAE), but to the square of the error, which gives relatively higher weight (penalty) to large errors/outliers, while smoothening the gradient for smaller errors.
#machine-learning #loss-function #deep-learning #artificial-intelligence #deep learning
