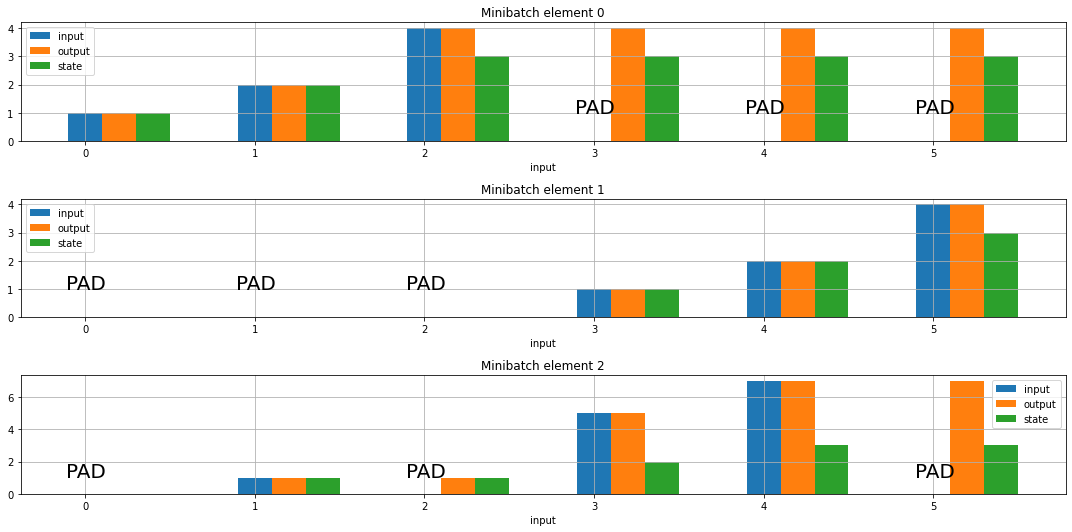
Keras has a masking feature that is oft mentioned in the context of RNNs. Here I give a quick visualization to show what it does and explain why that’s required.
If you are reading this you probably know that for computational efficiency as well as reducing too much stochasticity in the gradient descent path, learning is done in batches (which for some reason are christened mini-batches). If you are processing sequences then in most cases the sequences will not be of the same length and then to make batches you would “0-pad” the sequences. This can be done at the beginning or the end of the sequences.
Now if you do learning on such mini-batches your system would eventually learn to ignore the 0-padded entries but it will waste learning cycles. Thus, you should help your algorithm with this.
In Keras you can turn on masking by giving a mask to the layers that support it and the Embedding layer can even produce such a mask. You can find details in the tensorflow guide.
In this short note, I help you visualize what masking does in RNNs and its variants.
We consider the minibatch
inputs=tf.constant([[1,2,4,0,0,0],
[0,0,0,1,2,4],
[0,1,0,5,7,0]
])
#tensorflow #machine-learning #rnn #lstm #keras