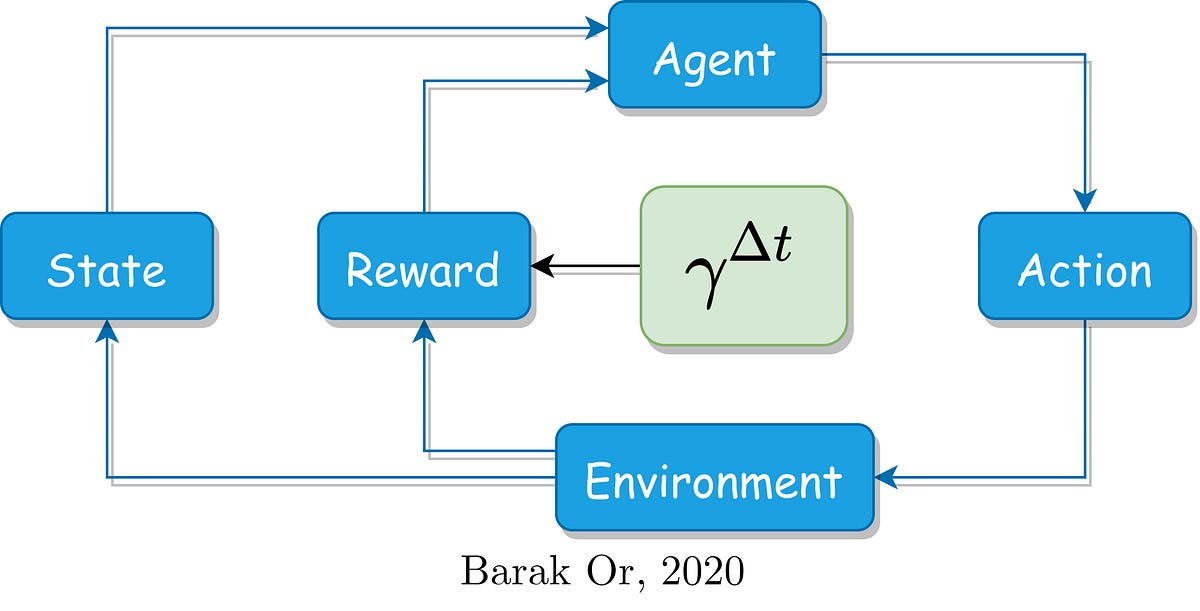
This post deals with the key parameter I found as a high influence: the discount factor. It discusses the time-based penalization to achieve better performances, where discount factor is modified accordingly.
I assume that if you land on this post, you are already familiar with the RL terminology. If it is not the case, then I highly recommend these blogs which provide a great background, before you continue: Intro1 and Intro2.
What is the role of the discount factor in RL?
The discount factor, **𝛾, **is a real value ∈ [0, 1], cares for the rewards agent achieved in the past, present, and future. In different words, it relates the rewards to the time domain. Let’s explore the two following cases:
- If **𝛾 **= 0, the agent cares for his first reward only.
- If **𝛾 **= 1, the agent cares for all future rewards.
Generally, the designer should predefine the discount factor for the scenario episode. This might raise many stability problems and can be ended without achieving the desired goal. However, by exploring some parameters many problems can be solved with converged solutions. For further reading on the discount factor and the rule of thumb for selecting it for robotics applications, I recommend reading: resource3.
#artificial-intelligence #optimization #deep-learning #machine-learning #reinforcement-learning #deep learning