Data is the fuel of every machine learning algorithm, on which statistical inferences are made and predictions are done. Consequently, it is important to collect the data, clean it and use it with maximum efficacy. A decent data sampling can guarantee accurate predictions and drive the whole ML project forward whereas a bad data sampling can lead to incorrect predictions. Before diving into the sampling techniques, let us understand what the population is and how does it differ from a sample?
The population is the assortment or the collection of the components which shares a few of the other characteristics for all intents and purposes. The total number of observations is said to be the size of the population
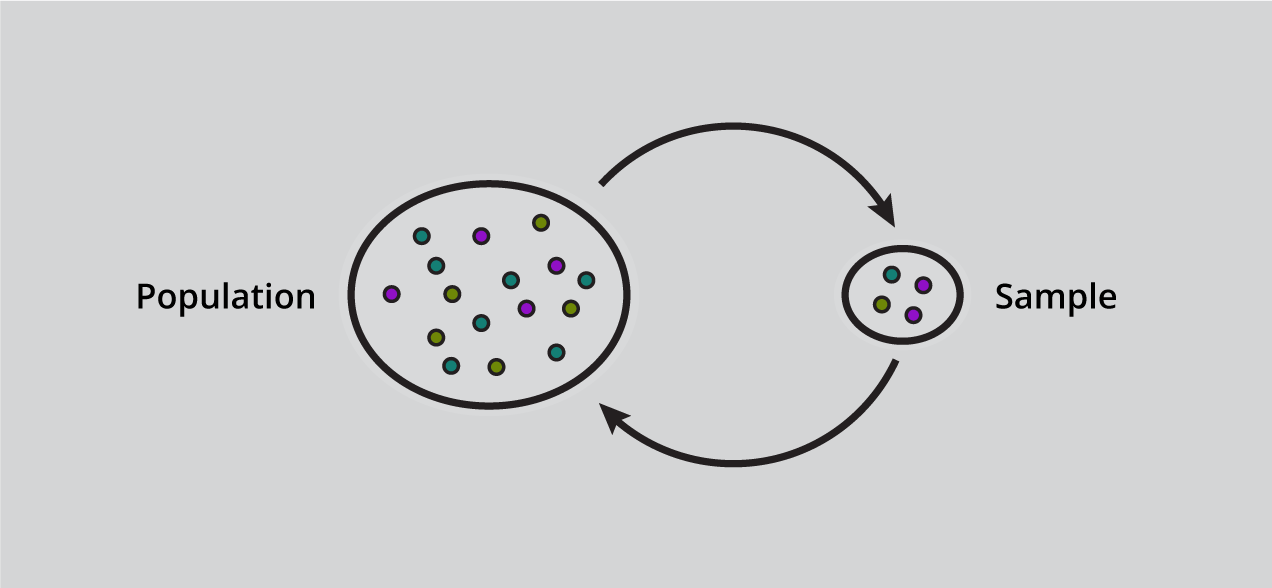
The sample is a subset of the population. The process of choosing a sample from a given set of the population is known as sampling. The number of components in the example is the sample size.
Data sampling refers to statistical approaches for picking observations from the domain to estimate a population parameter. Whereas data resampling refers to the drawing of repeated samples from the main or original source of data. It is the non-parametric procedure of statistical extrapolation. It produces unique sample distributions based on the original data and is used to improve the accuracy and intuitively measure the uncertainty of the population parameter.
Sampling methods can be divided into two parts:
- Probability sampling procedure
- Non-probability sampling procedure
The distinction between the two is that the example of determination depends on randomization. With randomization, each component persuades equivalent opportunity and is important for test for study.
#data-science
