When you’re working on Deep Learning algorithms you almost always require a large volume of data to train your model on. It’s inevitable since Deep Learning algorithms like RNN’s or GRU’s are data-hungry, and in order to converge they need their fair share of data. But what if there’s not enough data? This is not a rare situation to happen, in fact, when working in research you probably have to deal with it on a daily basis, or even if you are working on a new area/product where there’s not, yet, a lot of data available. How can you deal with this? Am I able to apply Machine Learning? Can I leverage the latest advances in Deep Learning?
There are two possible paths that we can choose from, and I’ll be covering them in the next sections — the Data Path and the Model Path.
Data Path
It may sound a bit obvious, but sometimes we miss the power of this kind of solution to solve small data problems — I’m talking about Data Augmentation. The idea behind Data Augmentation is — Points nearby a certain point (in hyperspace) represent a similar behavior. For eg: An image of a dog with increased contrast or brightness is still an image of a dog.
To utilize Data augmentation for a tabular dataset there are numerous methods available like:
- Cluster-based Over-Sampling
- Synthetic Minority Over-sampling Technique (SMOTE)
Let’s talk about SMOTE in more detail. To simplify we can define the concept behind SMOTE as “Birds of the same feather flock together”, which reduced in data terms means that data-points that are close to each other in the hyperspace represent similar behavior so they can be approximated as new data-points for the dataset.
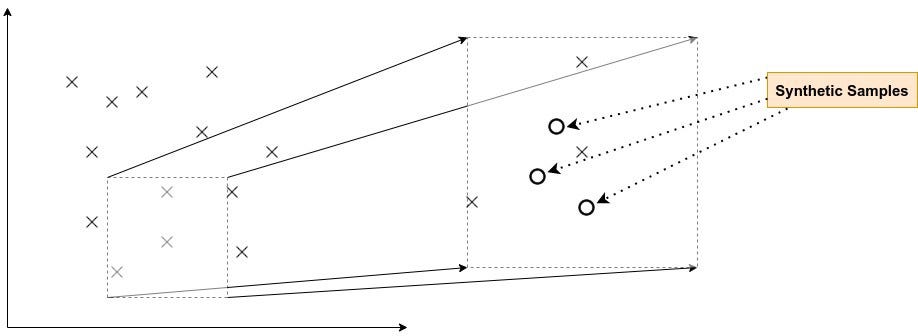
This technique works best when a few samples are synthesized from a bigger set. But, once you go past a certain threshold of approximating the synthetic samples, the likelihood of the samples starts to diverge. So you’ve to keep this in mind while implementing this.
But, once you go past a certain threshold of approximating the synthetic samples, the likelihood of the samples starts to diverge.
Let’s also talk about **Data Augmentation **in images. Looking at the image below, they all represent a parrot but they are all different since the demographics of the image like contrast, brightness, etc., changed, going from a single image to 12 images increasing your data volume 12x.
Off-course that we can also apply rotations, mirroring, and crop in order to augment the available images datasets. For this purpose, there are several libraries available such as OpenCV, PyTorch, and TensorFlow. Another one that is also quite interesting is albumentation, which you can see in action over this Colab notebook.
Generative Models for data augmentation
Generative models have proven a super-useful understanding of the data distribution, so much that today these models are the prime tool for Data Augmentation tasks.
#computer-science #machine-learning #deep-learning #data-science #data #deep learning