You must have heard that Apache Spark is a powerful distributed data processing engine. But do you know that Spark (with the help of Hive) can also act as a database? So, in this blog, we will learn how Apache Spark can be leveraged as a database by creating tables in it and querying upon them.
Introduction
Since Spark is a database in itself, we can create databases in Spark. Once we have a database we can create tables and views in that database.
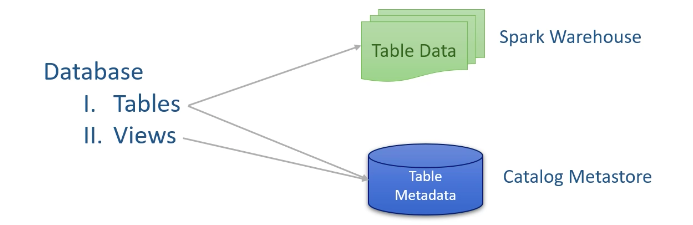
The table has got two parts – Table Data and Table Metadata. The table data resides as data files in your distributed storage. The metadata is stored in a meta-store called catalog. It includes schema info, table name, database name, column names, partitions and the physical location of actual data. By default, Spark comes with an in-memory catalog which is maintained per session. To persist it, Spark uses Apache Hive meta-store.
Spark Tables
In Spark, we have 2 types of tables-
1. Managed Tables
2. Unmanaged or External Tables
For managed tables, Spark manages both the table data and the metadata. It means that it creates the metadata in the meta-store and then writes the data inside a predefined directory location. This directory is the Spark SQL warehouse directory which is the base location for all the managed tables.
If we delete a managed table, Spark deletes both the metadata and table data.
Now, let’s come to the unmanaged tables. These are same as managed tables w.r.t metadata but differ in terms of data storage location. Spark only creates the metadata for these in the meta-store. When creating unmanaged tables, we must specify the location of the data directory for our table. This gives us the flexibility to store the data at a preferred location. These are useful when we want to use Spark SQL on some pre-existing data. If we delete an unmanaged table, Spark only deletes the metadata and doesn’t touch the table data. Makes sense!
We have some added benefits with managed tables such as bucketing and sorting. Future Spark SQL enhancements will also target managed tables and not unmanaged tables. As such, the rest of our discussion will only target managed tables.
#database #sql #spark #apache-spark #developer
