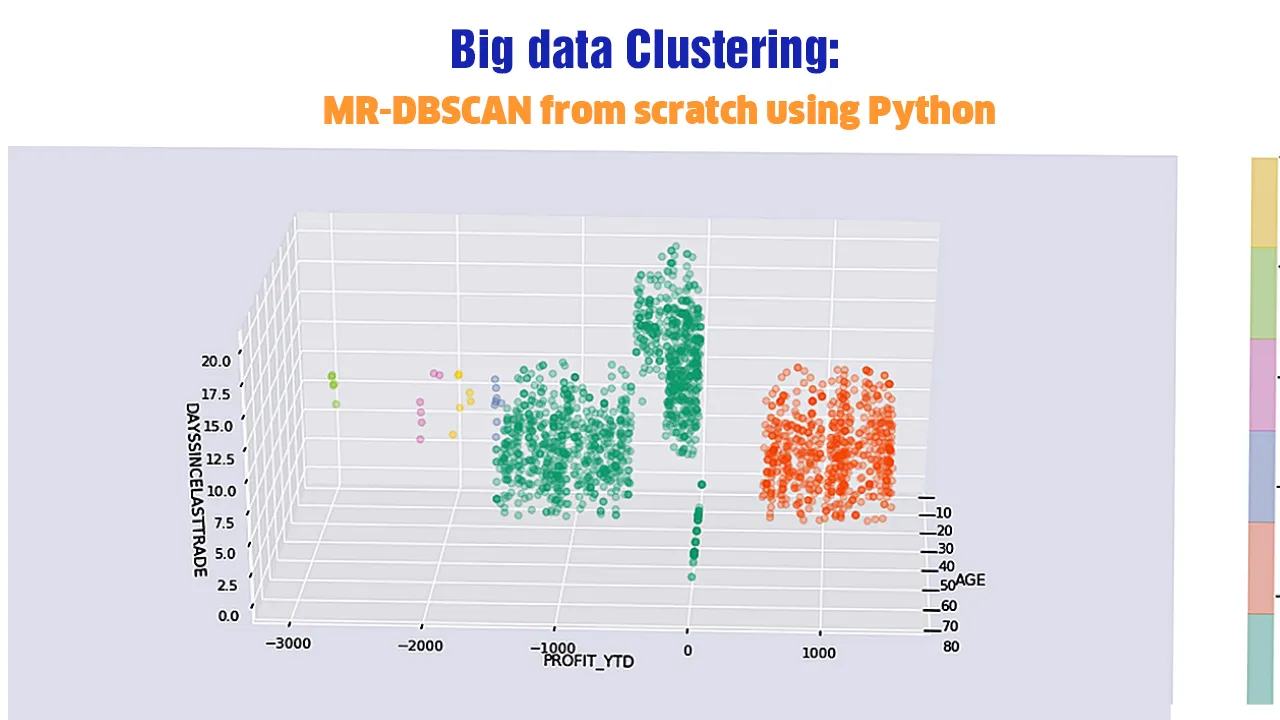
Clustering based on basic standards like density, shape, and size is very common. In a similar way, DBSCAN is an extensive method of the density-based clustering algorithm.
For MapReduce check this article (https://medium.com/@rrfd/your-first-map-reduce-using-hadoop-with-python-and-osx-ca3b6f3dfe78)
Algorithm description:
- Choose a random point p.
- Fetch all points that are density-reachable from p with respect to eps and minPts.
- A cluster is formed if p is a core point.
- Visit the next point of the dataset, if p is a border point and none of the points is density-reachable from p.
- Repeat the above process until all the points have been examined.
#mapreduce #big-data #partitioning #dbscan #clustering-algorithm #big data clustering: mr-dbscan from scratch using python
1.50 GEEK