In Part 1 of this series on data scientists are from Mars and software engineers are from Venus we examined the five key dimensions of difference between software and models. The natural follow on question to ask is — **So What? **Does it really matter if models are conflated with software and data scientists are treated as software engineers? After all for a large cross-section of the population, and more importantly the business world, the similarities between them are far more visible than their differences. In fact, Andrej Karpathy refers to this new way of solving problems using models as Software 2.0. If they are really the next iteration of software are these differences really consequential.
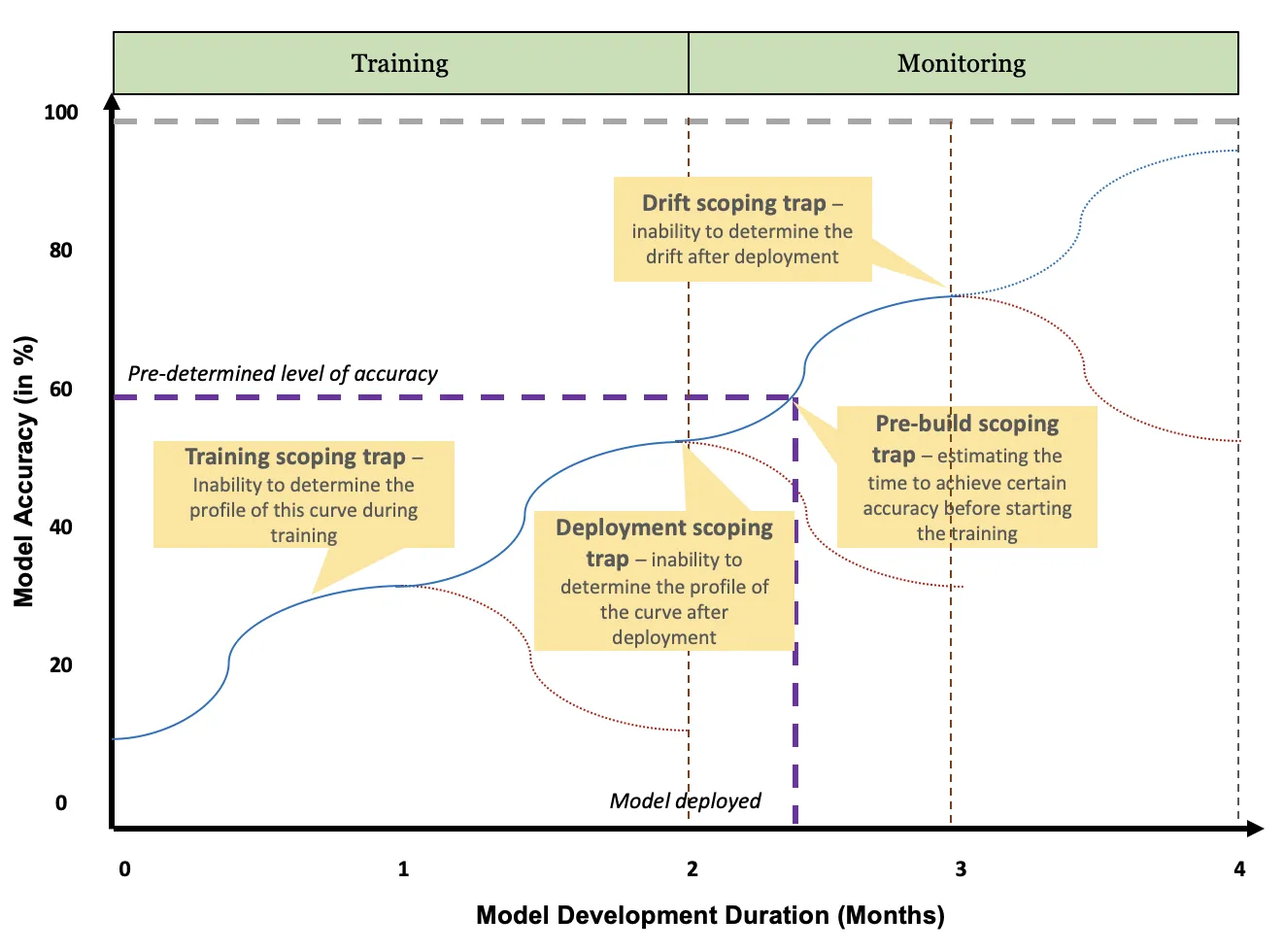
The challenges of building models is exasperated when we conflate models and software. In this blog, we describe the twelve ‘traps’ we face when we conflate the two and argue that we need to be cognizant of the differences and address them accordingly.
Data Trap
As we examined in our previous blog, models are formal mathematical representations that can be applied to or calibrated to fit data. Hence, data is the starting point for building a model. While test data is critical for building software, one can start building an algorithm from a given specification before collecting or preparing the test data.
However, when it comes to building models the data has to be of good quality (i.e., garbage in, garbage out), available in sufficient quantity, and for supervised learning models also labeled (i.e., a label is a response variable that is being predicted by the model). The data also needs to be fit for purpose. One example of this is that the data should be representative of the population that we will be using when the model is deployed in production. Recent examples of skin type and gender biases of facial recognition models underscores the importance of having a representative (and a statistically significant) dataset for building models. Such data biases are surprisingly common in practice.
We have seen the failure to address this challenge of gathering, curating, and labeling the necessary data needed to build a model as one of the significant traps of mistaking models to be similar to software. A number of companies eager to launch their AI or ML programs pay very little attention to this aspect and start building models with very little data. For example, a company recently wanted to build a NLP (natural language processing) model to extract structured information from documents with just eight PDF documents. The cost and the time required — especially from domain experts (e.g., legal experts or clinicians) — makes labeling a significant challenge. While techniques are evolving to learn from less data and also assist experts to label data as part of their normal work, having sufficient, good labeled data is still a significant departure from the way models are built vs how software is traditionally developed.
In summary, the data trap can be further categorized as data volume trap, data quality trap, data bias trap, and data labeling trap. A company can suffer from one or more of these traps. Getting a realistic sense of the data trap is critical to ensuring you don’t go down the wrong path and spend millions on your modeling effort and not realizing the expected returns. In addition, understanding these traps can also change the way you address your modeling effort by first collecting more labeled data or looking for alternative rule-based ways of solving the problems.
#scoping #agile-methodology #data-science #modeling