Originally published by Andres Vourakis at https://towardsdatascience.com/web-scraping-mountain-weather-forecasts-using-python-and-a-raspberry-pi-f215fdf82c6b
Web Scraping Mountain Weather Forecasts using Python and a Raspberry Pi. Extracting data from a website without an API. Go to the profile of ...
Motivation
Before walking you through the project, let me tell you a little bit about the motivation behind it. Aside from Data Science and Machine Learning, my other passion is spending time in the mountains. Planning a trip to any mountain requires lots of careful planning in order to minimize the risks. That means paying close attention to the weather conditions as the summit day approaches. My absolutely favorite website for this is Mountain-Forecast.com which gives you the weather forecasts for almost any mountain in the world at different elevations. The only problem is that it doesn’t offer any historical data (as far as I can tell), which can sometimes be useful when determining if it is a good idea to make the trip or wait for better conditions.
This problem has been in the back of my mind for a while and I finally decided to do something about it. Below, I’ll describe how I wrote a web scraper for Mountain-Forecast.com using Python and Beautiful Soup, and put it into a Raspberry Pi to collect the data on a daily basis.
if you’d rather skip to the code, then check out the repository on GitHub.
Web Scraping
Inspecting the Website
In order to figure out which elements I needed to target, I started by inspecting the source code of the page. This can be easily done by right clicking on the element of interest and selecting inspect. This brings up the HTML code where we can see the element that each field is contained within.

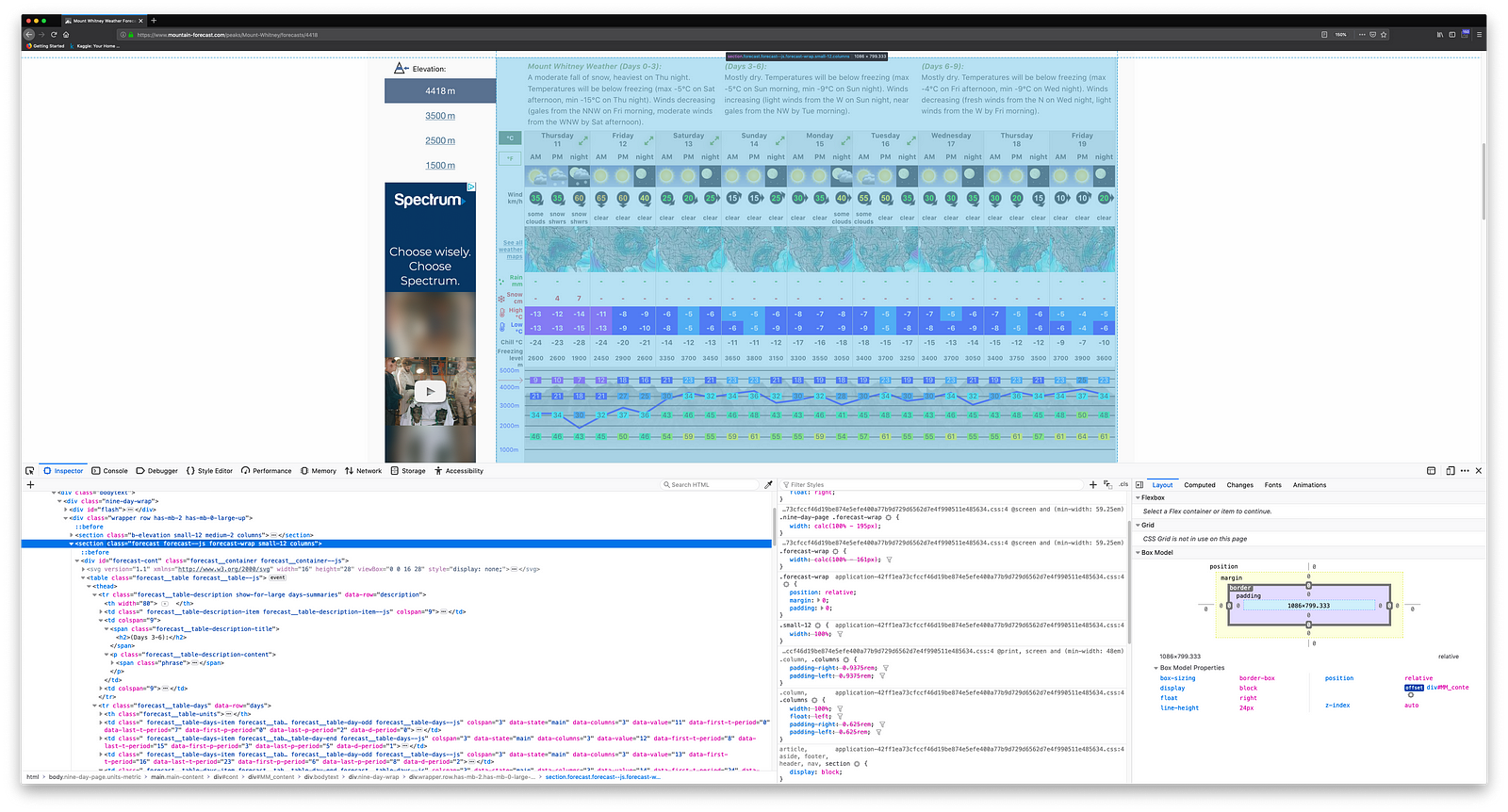
Lucky for me, the forecast information for every mountain is contained within a table. The only problem is that each day has multiple sub columns associated with it (i.e. AM, PM and night) and so I would need to figure out a way to iterate through them. In addition, since weather forecasts are provided at different elevations, I would need to extract the link for each one of them and scrape them individually.
Similarly, I inspected the directory containing the URLs for the highest 100 mountains in the United States.


This seemed like a much easier task since all I needed from the table were the URLs and Mountain Names, in no specific order.
Parsing the Web Page using Beautiful Soup
After familiarizing myself with the HTML structure of the page, it was time to get started.
My first task was to collect the URLs for the mountains I was interested in. I wrote a couple of functions to store the information in a dictionary, where the key is Mountain Name and the value is a list of all the URLs associated with it (URLs by elevation). Then I used the pickle module to serialize the dictionary and save it into a file so that it could be easily retrieved when needed. Here is the code I wrote to do that:
def load_urls(urls_filename):
""" Returns dictionary of mountain urls saved a pickle file """
full_path = os.path.join(os.getcwd(), urls_filename)
with open(full_path, 'rb') as file:
urls = pickle.load(file)
return urls
def dump_urls(mountain_urls, urls_filename):
“”" Saves dictionary of mountain urls as a pickle file “”"
full_path = os.path.join(os.getcwd(), urls_filename)
with open(full_path, 'wb') as file:
pickle.dump(mountain_urls, file)
def get_urls_by_elevation(url):
“”" Given a mountain url it returns a list or its urls by elevation “”"
base_url = 'https://www.mountain-forecast.com/'
full_url = urljoin(base_url, url)
time.sleep(1) # Delay to not bombard the website with requests
page = requests.get(full_url)
soup = bs(page.content, 'html.parser')
elevation_items = soup.find('ul', attrs={'class':'b-elevation__container'}).find_all('a', attrs={'class':'js-elevation-link'})
return [urljoin(base_url, item['href']) for item in elevation_items]
def get_mountains_urls(urls_filename = ‘mountains_urls.pickle’, url = ‘https://www.mountain-forecast.com/countries/United-States?top100=yes’):
“”" Returs dictionary of mountain urls
If a file with urls doesn't exists then create a new one using "url" and return it
"""
try:
mountain_urls = load_urls(urls_filename)
except: # Is this better than checking if the file exists? Should I catch specific errors?
directory_url = url
page = requests.get(directory_url)
soup = bs(page.content, 'html.parser')
mountain_items = soup.find('ul', attrs={'class':'b-list-table'}).find_all('li')
mountain_urls = {item.find('a').get_text() : get_urls_by_elevation(item.find('a')['href']) for item in mountain_items}
dump_urls(mountain_urls, urls_filename)
finally:
return mountain_urls
My next task was to collect the weather forecast for each mountain in the dictionary. I used requests to get the content of the page and beautifulsoup4 to parse it.
page = requests.get(url)
soup = bs(page.content, ‘html.parser’)Get data from header
forecast_table = soup.find(‘table’, attrs={‘class’: ‘forecast__table forecast__table–js’})
days = forecast_table.find(‘tr’, attrs={‘data-row’: ‘days’}).find_all(‘td’)Get rows from body
times = forecast_table.find(‘tr’, attrs={‘data-row’: ‘time’}).find_all(‘td’)
winds = forecast_table.find(‘tr’, attrs={‘data-row’: ‘wind’}).find_all(‘img’) # Use “img” instead of “td” to get direction of wind
summaries = forecast_table.find(‘tr’, attrs={‘data-row’: ‘summary’}).find_all(‘td’)
rains = forecast_table.find(‘tr’, attrs={‘data-row’: ‘rain’}).find_all(‘td’)
snows = forecast_table.find(‘tr’, attrs={‘data-row’: ‘snow’}).find_all(‘td’)
max_temps = forecast_table.find(‘tr’, attrs={‘data-row’: ‘max-temperature’}).find_all(‘td’)
min_temps = forecast_table.find(‘tr’, attrs={‘data-row’: ‘min-temperature’}).find_all(‘td’)
chills = forecast_table.find(‘tr’, attrs={‘data-row’: ‘chill’}).find_all(‘td’)
freezings = forecast_table.find(‘tr’, attrs={‘data-row’: ‘freezing-level’}).find_all(‘td’)
sunrises = forecast_table.find(‘tr’, attrs={‘data-row’: ‘sunrise’}).find_all(‘td’)
sunsets = forecast_table.find(‘tr’, attrs={‘data-row’: ‘sunset’}).find_all(‘td’)Iterate over days
for i, day in enumerate(days):
current_day = clean(day.get_text())
elevation = url.rsplit(‘/’, 1)[-1]
num_cols = int(day[‘data-columns’])if current_day != '': date = str(datetime.date(datetime.date.today().year, datetime.date.today().month, int(current_day.split(' ')[1]))) # Avoid using date format. Pandas adds 00:00:00 for some reason. Figure out better way to format # Iterate over forecast for j in range(i, i + num_cols): time_cell = clean(times[j].get_text()) wind = clean(winds[j]['alt']) summary = clean(summaries[j].get_text()) rain = clean(rains[j].get_text()) snow = clean(snows[j].get_text()) max_temp = clean(max_temps[j].get_text()) min_temp = clean(min_temps[j].get_text()) chill = clean(chills[j].get_text()) freezing = clean(freezings[j].get_text()) sunrise = clean(sunrises[j].get_text()) sunset = clean(sunsets[j].get_text()) rows.append(np.array([mountain_name, date, elevation, time_cell, wind, summary, rain, snow, max_temp, min_temp, chill, freezing, sunrise, sunset]))
As you can see from the code, I manually saved each element of interest into its own variable instead of iterating through them. It wasn’t pretty but I decided to do it that way since I wasn’t interested in all of the elements (i.e. weather maps and freezing scale) and there were a few of them that needed to be handled differently than the rest.
Saving the data
Since my goal was to scrape daily and the forecasts get updated everyday, it was important to figure out a way to update old forecasts instead of creating duplicates and append the new ones. I used the pandas module to turn the data into a DataFrame (a two-dimensional data structure consisting or rows and columns) and be able to easily manipulate it and then save it as a CSV file. Here is what the code looks like:
def save_data(rows):
“”" Saves the collected forecasts into a CSV fileIf the file already exists then it updates the old forecasts as necessary and/or appends new ones. """ column_names = ['mountain', 'date', 'elevation', 'time', 'wind', 'summary', 'rain', 'snow', 'max_temperature', 'min_temperature', 'chill', 'freezing_level', 'sunrise', 'sunset'] today = datetime.date.today() dataset_name = os.path.join(os.getcwd(), '{:02d}{}_mountain_forecasts.csv'.format(today.month, today.year)) # i.e. 042019_mountain_forecasts.csv try: new_df = pd.DataFrame(rows, columns=column_names) old_df = pd.read_csv(dataset_name, dtype=object) new_df.set_index(column_names[:4], inplace=True) old_df.set_index(column_names[:4], inplace=True) # Update old forecasts and append new ones old_df.update(new_df) only_include = ~old_df.index.isin(new_df.index) combined = pd.concat([old_df[only_include], new_df]) combined.to_csv(dataset_name) except FileNotFoundError: new_df.to_csv(dataset_name, index=False)
Once the data collection and manipulation was done, I ended up with this table:

Running the Scraper on Raspberry Pi
The Raspberry Pi is a low cost, credit-card sized computer that can be used for a variety of projects like, retro-gaming emulation, home automation, robotics, or in this case, web-scraping. Running the scraper on the Raspberry Pi can be a better alternative to leaving your personal desktop or laptop running all the time, or investing on a server.
Setting it up
First I needed to install an Operating System on the Raspberry Pi and I chose Raspbian Stretch Lite, a Debian-based operating system without a graphical desktop, just a terminal.
After installing Raspbian Stretch Lite, I used the the command sudo raspi-config to open up the configuration tool and change the password, expand filesystem, change host name and enable SSH.

Finally, I used sudo apt-get update && sudo apt-get upgrade to make sure everything was up-to-date and proceeded to install all of the dependencies necessary to run my script (i.e. Pandas, Beautiful Soup 4, etc…)
Automating the script
In order to schedule the script to run daily, I used cron, a time-based job scheduler in Unix-like computer operating systems (i.e. Ubuntu, Raspbian, macOS, etc…). Using the following command the script was scheduled to run daily at 10:00 AM.
0 10 * * * /usr/bin/python3 /home/pi/scraper.py
This is what the final set-up looks like:

Since SSH is enabled on the Raspberry Pi, I can now easily connect to it via terminal (no need for an extra monitor and keyboard) using my personal laptop or phone and keep an eye on the scraper.
I hope you enjoyed this walk through and it inspired you to code your own Web Scraper using Python and a Raspberry Pi. If you have any questions or feedback, I’ll be happy to read them in the comments below :)
Originally published by Andres Vourakis at https://towardsdatascience.com/web-scraping-mountain-weather-forecasts-using-python-and-a-raspberry-pi-f215fdf82c6b
Thanks for reading :heart: If you liked this post, share it with all of your programming buddies! Follow me on Facebook | Twitter
Learn More
☞ Machine Learning with Python, Jupyter, KSQL and TensorFlow
☞ Introduction to Python Microservices with Nameko
☞ Comparing Python and SQL for Building Data Pipelines
☞ Python Tutorial - Complete Programming Tutorial for Beginners (2019)
☞ Python and HDFS for Machine Learning
☞ Build a chat widget with Python and JavaScript
☞ Complete Python Bootcamp: Go from zero to hero in Python 3
☞ Learn Python by Building a Blockchain & Cryptocurrency
☞ Python and Django Full Stack Web Developer Bootcamp
☞ The Python Bible™ | Everything You Need to Program in Python
☞ Learning Python for Data Analysis and Visualization
☞ Python for Financial Analysis and Algorithmic Trading
☞ The Modern Python 3 Bootcamp
#python #data-science
