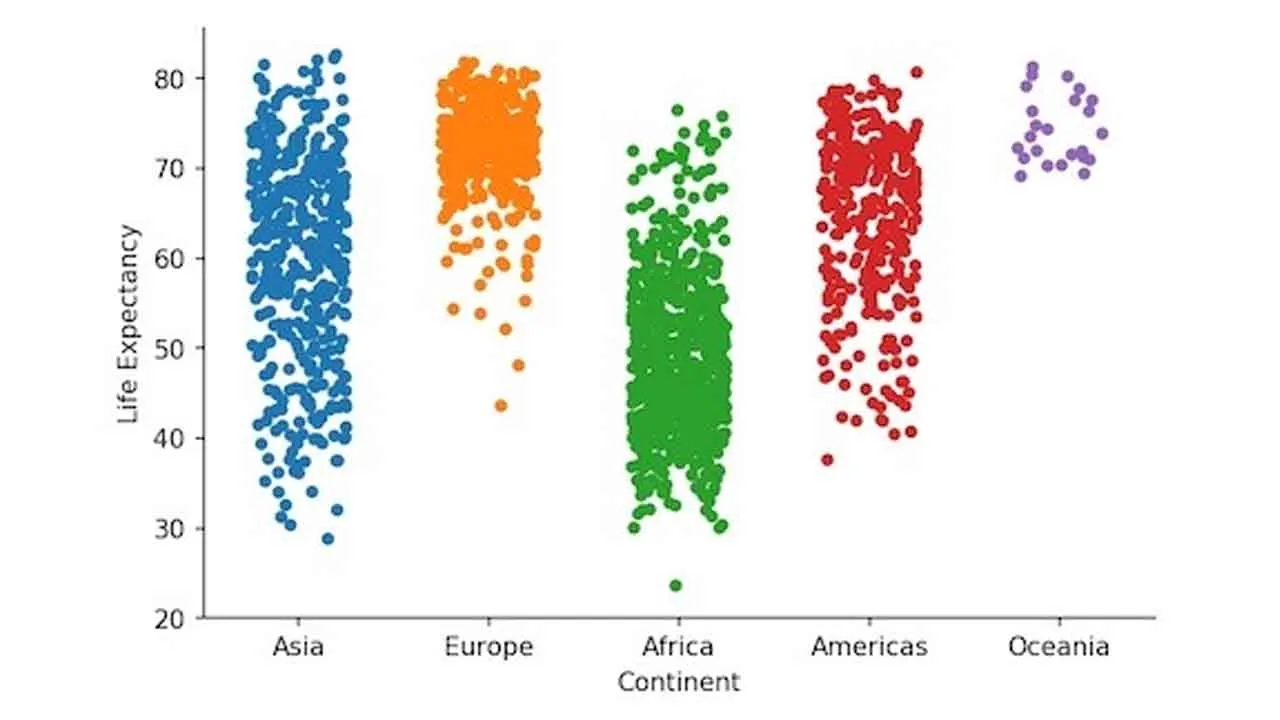
The Data
In this post we will use one of Seaborn’s conveniently available datasets about the Titanic, which I’m sure many readers have seen before. Seaborn has quite a few datasets ready to be loaded into Python to practice with; they are great for practicing data processing, exploration, and basic machine learning techniques.
titanic = sns.load_dataset('titanic')
titanic.head()

titanic.head()
titanic.info()
titanic['species'].unique()
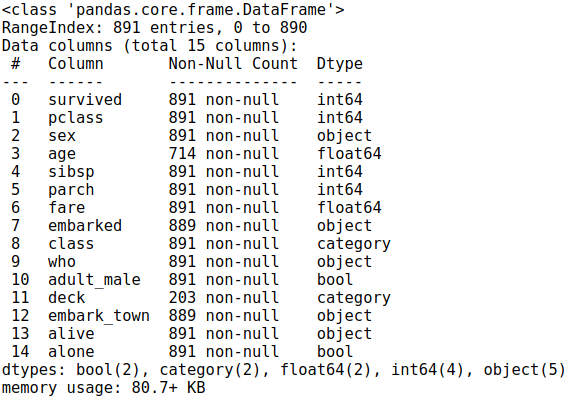
This data set is great because it has a decent number of entries — almost 900 — while also having an interesting story to dig into. There are lots of questions to ask and relationships between variables to explore making it a great example data set. Most critical for this article is that there is also a good mix of numerical and categorical variables to explore.
#data-visualization #seaborn #python #python-programming