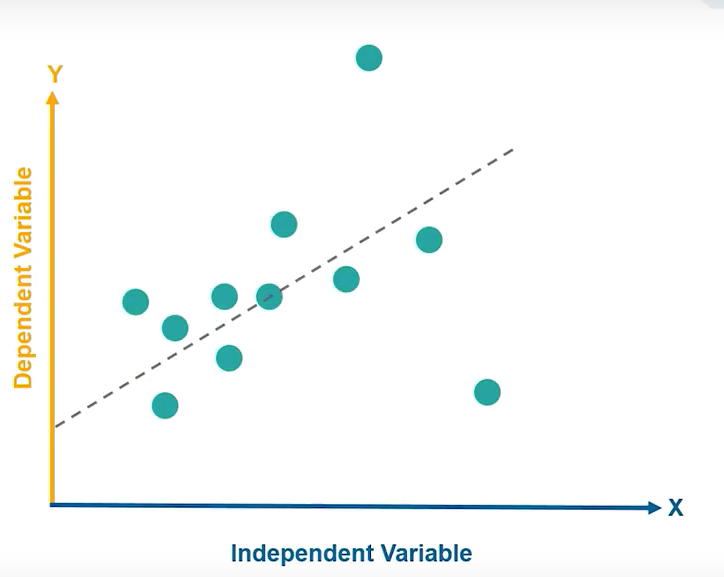
Regression is the study of dependence — A Predictive modelling technique
- It attempts to find the relationship between a DEPENDENT variable “Y” and an INDEPENDENT variable “X”.
- (Note: Y should be a continuous variable while X can be categorical or continuous)
- There are two types of regression —_ Simple Linear Regression and Multiple Linear Regression._
- Simple linear regression will have one independent variable(predictor).
- Multiple linear regression will have more than one independent variable (predictors).
- In a nutshell — Linear Regression maps a continuous X to a continuous Y.
1. APPLICATIONS OF REGRESSION ANALYSIS:
- To determine strength of independent variables (predictors)
— Example: Relationship between Age & Income
2. To forecast effects
— Example: Effect on sale income for 1000$ spent on marketing
3. To forecast trends
— Example: Predicting price of bitcoin in the next 6 months
2. KEY POINTS FOR LINEAR REGRESSION:
3. SELECTION CRITERIA FOR LINEAR REGRESSION:
- Classification & Regression Capabilities:
- Regression models predict continuous variables (Eg: Predict the temperature of a city)
- Once it is known that the aim is to classify data — we choose Logistic Regression.
- Linear Regression is not suitable for classification because “**the idea of fitting a straight line in case of a polynomial is a challenging task. **”
2. Data Quality:
- Each missing value removes one data point that could optimize the regression.
- In simple linear regression, the outliers can significantly disturb the outcome. (i.e. removing outliers enhances the model greatly)
3. Computational Complexity:
- It is not expensive computation-wise as compared to decision tree (or) clustering.
4. Comprehensible & Transparent:
- Easy to comprehend and understand
#data #linear-regression #data-science #machine-learning #towards-data-science
1.25 GEEK