Get comfortable, it’s going to take you several minutes to read but hopefully, you’ll stick with me along the whole article. I’m gonna walk you through a foundational task that you as data scientist/machine learning engineer must know how to perform because at some point of your career you’ll be required to do so. In the context of this article, I’ll assume you have a basic understanding of what I’m going to talk in the next lines. I’ll be stacking layers of concepts as I move forward, keeping a very low-level language — don’t worry if you fell a little lost between lines, later I will probably clarify your doubts. The main idea is for you to understand what I’ll be explaining. That being said, let’s get hands-on (Btw, don’t miss any detail and download the whole project from my repo.)
I’ll start by defining the first unusual term in the title: **Sentiment Analysis **is a very frequent term within text classification and is essentially to use natural language processing (quite often referred simply as NLP)+ machine learning to interpret and classify emotions in text information. Imagine the task of determining whether a product’s review is positive or negative; you could do it yourself just by reading it, right? But what happens when the company you work for sells 2k products every single day? Are you pretending to read all the reviews and manually classify them? Let’s be honest, your job would be the worst ever. There’s where Sentiment Analysis comes in and makes your life and job easier.
Let’s get into the matter
There are several ways to implement Sentiment Analysis and each data scientist has his/her own preferred method, I’ll guide you through a very simple one so you can understand what it involves, but also suggest you some others that way you can research about them. Let’s place first things first: If you are not familiar with Machine Learning, you must know all algorithms are only able to understand and process numeric data (particularly floating point data), thus you cannot feed them with text and wait for them to solve your problems; instead, you’ll have to make several transformations to your data until it reaches a representative numeric shape. The common and most basic steps are:
- Remove URLs and email addresses from every single sample — because they won’t add meaningful value.
- Remove punctuation signs — otherwise your model won’t understand that “good!” and “good” are actually meaning the same thing.
- Lowercase all text — because you want to make the input text as generic as possible and avoid that, for example, a “Good” which is at the beginning of a phrase to be understood differently than the “good” in another sample.
- Remove stop-words — because they only add noise and won’t make the data more meaningful. Btw, stop-words refer to the most common words in a language, such as “I”, “have”, “are” and so on. I hope you get the point because there’s not an official stop-words list out there.
- Stemming/Lemmatizing: This step is optional, but for most of data scientist considered as crucial. I’ll show you that it’s not THAT relevant to achieve good results. Stemming and lemmatizing are very similar tasks, both look forward to extract the root words from every word of a sentence of the corpus data. Lemmatizing generally returns valid words (that exist) while stemming techniques return (most of the times) shorten words, that’s why lemmatizing is used more in real world implementations. This is how lemmatizers vs. stemmers work: suppose you want to find the root word of ‘caring’: ‘Caring’ -> Lemmatization -> ‘Care’. In the other hand: ‘Caring’ -> Stemming -> ‘Car’; did you get the point? You can research about both and obviously implement any if the business requires it.
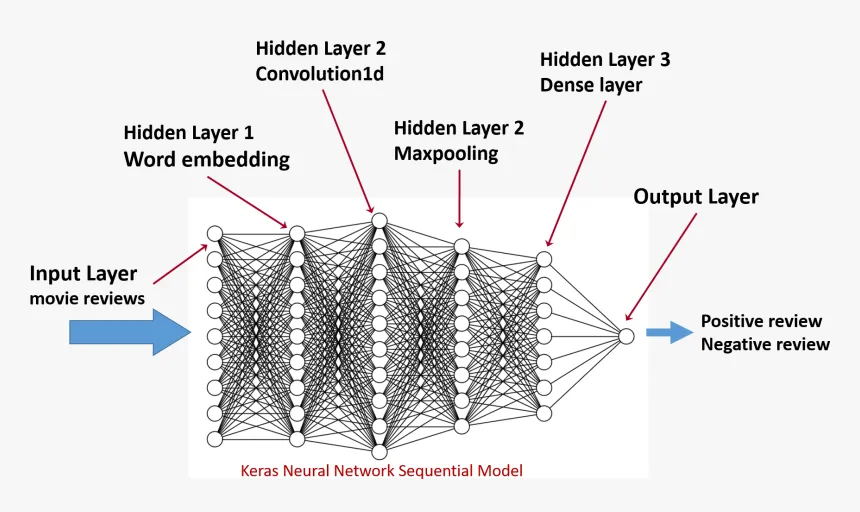
- Transform dataset (text) into numeric tensors — Usually referred as vectorization. If you recall some lines above, I explained that like all other neural networks, deep-learning models don’t take as input raw text: they only work with numeric tensors, that’s why this step is not negotiable. There are multiple ways to do so; for example, if you’re going to use a classic ML model (not DL) then you definitely should go with CountVectorizer, TFIDF Vectorizer or just the basic but not so good approach: Bag-Of-Words. It’s up to you. However, if you’re going to implement Deep Learning you might know that the best way is to turn your text data (that can be understood as sequences of word or sequences of characters) into low-dimensional floating-point vectors — don’t worry, I’ll explain this in a bit.
#neural-networks #machine-learning #data-science #sentiment-analysis #deep-learning