The LeNet architecture used 5x5 convolutions, AlexNet used 3x3, 5x5, 11x11 convolutions and VGG used some other mix of 3x3, and 5x5 convolutions. But the questions that deep learning scientists were worried about were which combination of convolutions to use in different datasets to get the best results.
For example, if we pick 5x5 convolutions, we end up with a fair number of parameters, there are a lot more multiplications involved, and they need a lot of parameters and are very slow, but on the other hand, it is very expressive. But if we pick 1x1 convolutions, it is much faster and does not need much memory, but maybe it does not work so well. Keeping these questions in mind, a brilliant idea was proposed in the Google LeNet paper — why not just pick them all, and stack them up in various convolutional blocks. It is also called the Inception paper, based on the movie Inception, and its famous dialogue — ‘we need to go deeper’.
Link to Inception paper — https://arxiv.org/abs/1409.4842
Inception Blocks:
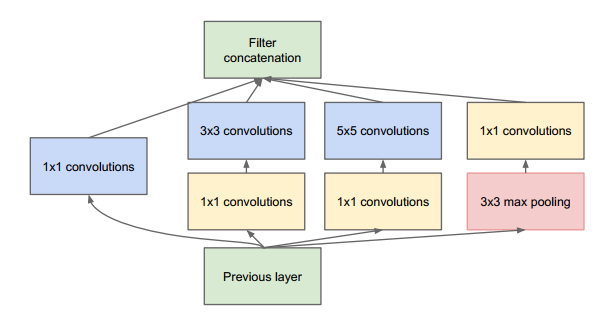
Figure 2. The Inception Block (Source: Image from the original paper)
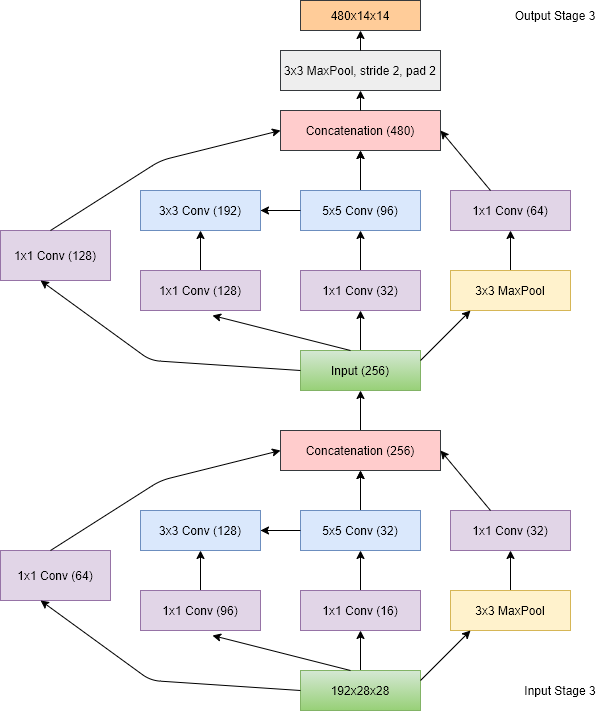
The inception block has it all. It has 1x1 convolutions followed by 3x3 convolutions, it has 1x1 convolutions followed by 5x5 convolutions, it has a 3x3 max pool layer followed by a 1x1 convolutions and it has a single 1x1 convolution. The idea is that if we use all the convolutions and pooling in a block, some of them will be efficient enough to extract some meaningful information from the images. To make sure that the image dimensions are maintained, the 3x3 convolutions have a padding of 1, and the 5x5 layer has a padding of 2 so that the input and the output images have the same size. And finally, they are all stacked together.
#computer-vision #deep-learning #artificial-intelligence #machine-learning #neural-networks