In this article, you will learn what quantization is, why do we need quantization, different types of quantization, and then build a quantized aware training deep learning model in Tensorflow.

Photo by israel palacio on Unsplash
What is Quantization?
Quantization is the process of transforming a deep learning model parameters: weights, activations, and biases from a higher floating-point precision to a lower bit representation.
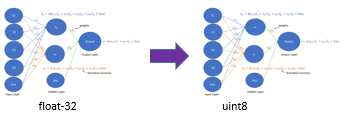
Quantizing weights, biases, and activations from float32 to uint8
Why do we need Quantization?
Quantization helps with model compression and reduced latency.
Models size can be compressed by a factor of 4. If your TF core deep learning Model is 40MB in size, it can be reduced to 10MB_. _Reduction in model size makes the model light-weight, which reduces the amount of computation and required less memory resulting in reduced latencies.
Quantized models
- Take less space
- Have faster download time on networks with lower bandwidth
- Occupy less memory for the Model to have faster inferences
- Reduced power consumption
Quantized models have reduced size and improved latency however there is a slight trade-off with the accuracy
What are the different types of Quantization?
You can currently apply two types of Quantization to your deep learning models.
- Quantize Aware Training: Quantization aware training is applied to the pre-trained model resulting in the Quantize Aware model. Quantize aware training ensures that forward pass matches the precision for both training and inference time. You can generate the quantize awareness for the entire model or only parts of it.
- Post Training Quantization: Quantization is applied to an already trained TensorFlow model using the TensorFlow Lite format. You can apply post-training dynamic range quantization, float16 quantization, or full integer quantization. In post-training quantization, weights are quantized post-training, and the activations are quantized dynamically at inference time.
#machine-learning #tensorflow #quantization #edge-computing #deep-learning