Avoid the mistake of overfitting and underfitting.
As a machine learning practitioner, it is important to have a good understanding of how to build effective models with high accuracy. A common pitfall in training a model is overfitting and underfitting.
Let us look at these topics so the next time you build a model, you would exactly know how to avoid the mistake of overfitting and underfitting.
Bias-Variance Trade-off
The two variables to measure the effectiveness of your model are bias and variance.
Please know that we are talking about the effectiveness of the model. If you are wondering about model validation, that is something we will discuss in another article.
_Bias _is the error or difference between points given and points plotted on the line in your training set.
_Variance _is the error that occurs due to sensitivity to small changes in the training set.
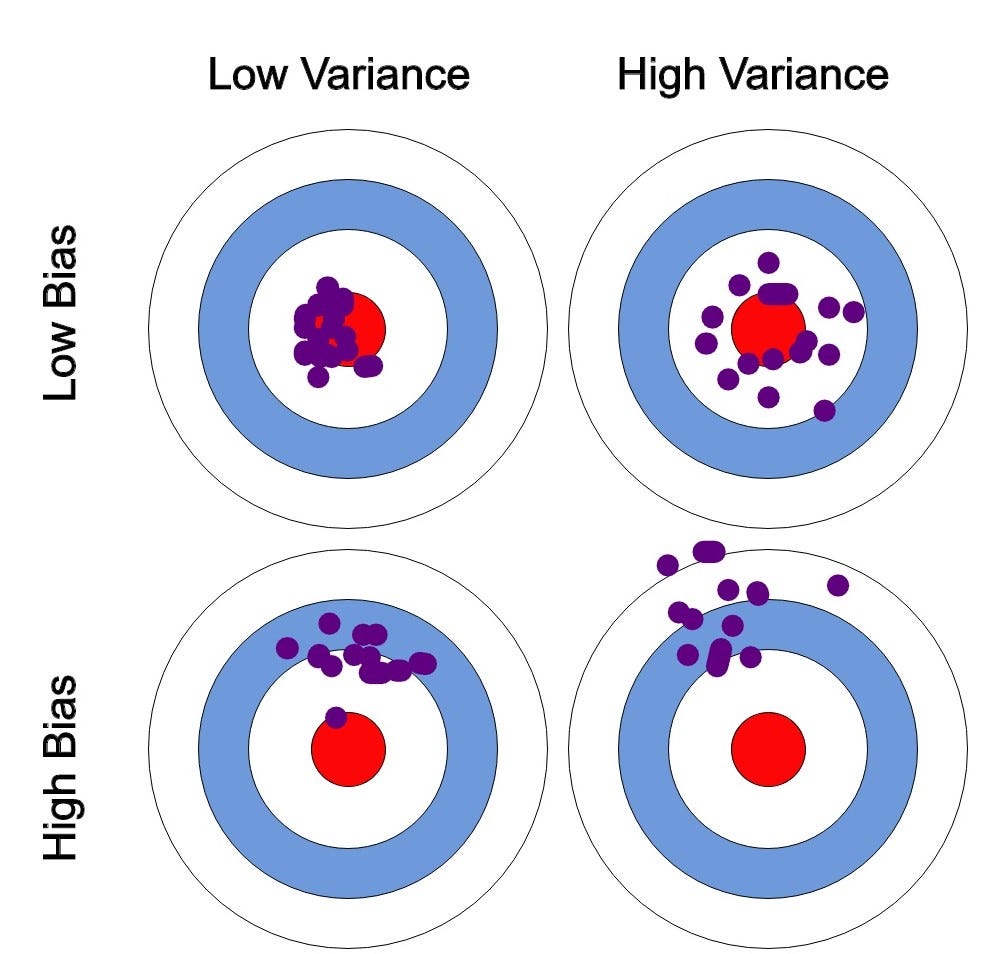
Bias-Variance. Image by the author.
I’ll be explaining bias-variance further with the help of the image above. So please follow along.To simply things, let us say, the error is calculated as the difference between predicted and observed/actual value. Now, say we have a model that is very accurate. This means that the error is very less, indicating a **low bias and low variance. **(As seen on the top-left circle in the image).
To simply things, let us say, the error is calculated as the difference between predicted and observed/actual value. Now, say we have a model that is very accurate. This means that the error is very less, indicating a **low bias and low variance. **(As seen on the top-left circle in the image).
If the variance increases, the data is spread more which results in lower accuracy. (As seen on the top-right circle in the image).
If the bias increases, the error calculated increases. (As seen on the bottom-left circle in the image).
High variance and high bias indicate that data is spread with a high error. (As seen on the bottom-right circle in the image)
This is Bias-Variance Tradeoff. Earlier, I defined bias as a measure of error between what the model captures and what the available data is showing, and variance being the error from sensitivity to small changes in the available data. A model having high variance captures random noise in the data.
We want to find the best fit line that has low bias and low variance. (As seen on the top-left circle in the image).
#predictions #machine-learning #education #artificial-intelligence #data-science
